Termos e Definições - Governança de Dados
Livro com termos e definições relacionados à gestão e governança de dados.
- #Referências
- Gestão de Dados
- Governança de Dados
- Glossário de Negócios
- Gerência de Dados Mestres e de Referência
- Business Intelligence
- Data Warehouse
- Data Warehousing
- Data Mart
- Big Data
- Tecnologias de Big Data
- Big Data vs Data Warehouse
- Análise de big data (Big data analytics)
- Data Lake
- Data Lakehouse
- Data Mesh
- Data Hub
- Integração e Governança de Dados
- Qualidade de Dados
- Linhagem de Dados
- ETL
- Staging Area
- EDW e Modelagem Dimensional
- Modelagem Dimensional
- Arquitetura de Barramento do Enterprise Data Warehouse
- Matriz de Barramento
- Tabela Fato
- Tabela de Dimensão
- Star Schema
- Tabela Fato sem Fato
- Tabela Fato de Snapshot Periódico
- Fatos Conformados
- Chaves Dimensionais
- Tabela Fato Transacional
- Tabela Fato de Snapshot Acumulado
- Natural Key
- Dimensões de Etapa (Step Dimensions)
- Tabelas Fato Agregadas
- Fatos Aditivos
- Dimensões Multivaloradas e Tabelas Ponte (bridge table)
- Tabelas Fato Consolidadas
- Fatos Agregados e Atributos de Dimensões
- Dimensões Genéricas Abstratas
- Dimensões de comentário
- Dimensões de Auditoria
- Dimensão Conformada
- Dimensões reduzidas (Shrunken Dimensions)
- Slowly Changing Dimensions
- Dimensões Degeneradas
- Mantendo a Granularidade na Modelagem Dimensional
- Pense Dimensionalmente
- Schemas de Eventos de Erros
- Surrogate Key
- Data Profiling
#Referências
- AMAZON. What is Apache Spark?. Disponível em: <https://aws.amazon.com/big-data/what-is-spark/>. Acesso em: 09 de março de 2022.
- AMAZON. What is a data lake?. Disponível em: <https://aws.amazon.com/big-data/datalakes-and-analytics/what-is-a-data-lake/>. Acesso em: 07 de março de 2022.
- AMAZON. What is Hadoop?. Disponível em: <https://aws.amazon.com/emr/details/hadoop/what-is-hadoop/>. Acesso em: 09 de março de 2022.
- ANAND, K.. Can Big Data replace an EDW?. Disponível em: <https://mastechinfotrellis.com/blog/can-big-data-replace-edw. Publicado em: 23 de Julho de 2019. Acesso em: 08 de março de 2022.
- ARMBRUST, M., GHODSI, A., XIN, R., ZAHARIA, M. Lakehouse: A New Generation of Open Platforms that Unify Data Warehousing and Advanced Analytics. 11th Annual Conference on Innovative Data Systems Research. 2021.
- BARBIERI, C. Governança de Dados: Práticas, conceitos e novos caminhos. Rio de Janeiro: Alta Books, 2019.
- BEGOLI, B., GOETHERT, I. KNIGHT, K. A Lakehouse Architecture for the Management and Analysis of Heterogeneous Data for Biomedical Research and Mega-biobanks. 2021 IEEE International Conference on Big Data (Big Data). P. 4643-4651. 2021.
- DAMA INTERNATIONAL. DAMA-DMBOK: Data Management Body of Knowledge (2nd Edition). Denville, NJ, USA. Technics Publications. 2017.
- DEHGHANI, Z.. How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh. Disponível em: <https://martinfowler.com/articles/data-monolith-to-mesh.html>. Publicado em: 20 de maio de 2019. Acesso em: 15 de março de 2022.
- GANDOMI, A., HAIDER, M. Beyond the hype: Big data concepts, methods, and analytics. International Journal of Information Management. V. 35, P. 137-144. 2015.
- KIMBALL, R., ROSS, M. The Kimball Group Reader: Relentlessly Practical Tools for Data Warehousing and Business Intelligence. Indianapolis. Wiley. 2010. 565 p.
- KIMBALL, R., ROSS, M. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling (3nd Edition). Indianapolis. Wiley. 2013. 720 p.
- PEREIRA, D., OLIVEIRA, P., RODRIGUES, F. Data warehouses in MongoDB vs SQL Server: A comparative analysis of the querie performance. Information Systems and Technologies (CISTI), 10th Iberian Conference. P. 1–7. 2015.
- INMON, W. H. Building the Data Warehouse. Indianapolis. Wiley. 2005. 428 p.
- INMON, B. Data Lake architecture: Designing the Data Lake and avoiding the garbage dump. Indianapolis. Technics Publications. 2016. 168 p.
- KHINE, P. P., WANG, Z. S. Data lake: a new ideology in big data era. ITM Web of Conferences, V 17. 2018.
- MILOSLAVSKAYA, N., TOLSTOY, A. Big data, fast data and data lake concepts. 7Th annual international conference on biologically inspired cognitive architectures (BICA 2016). NY, USA. Procedia Computer Science. V. 88, P. 1–6. 2016.
- MICROSOFT. What is business intelligence?. Disponível em: <https://powerbi.microsoft.com/en-us/what-is-business-intelligence/>. Acesso em: 07 de março de 2022.
- TABLEAU. Business Intelligence: What It Is, How It Works, Its Importance, Examples, & Tools. Disponível em: <https://www.tableau.com/learn/articles/business-intelligence>. Acesso em: 07 de março de 2022.
- GARTNER. Business Intelligence (BI) Platforms. Disponível em: <https://www.gartner.com/en/information-technology/glossary/bi-platforms>. Acesso em: 07 de março de 2022.
- GARTNER. Master Data Management (MDM). Disponível em: <https://www.gartner.com/en/information-technology/glossary/master-data-management-mdm>. Acesso em: 18 de março de 2022.
- MONGODB. Database Scaling. Disponível em: <https://www.mongodb.com/databases/scaling>. Acesso em: 09 de março de 2022.
- SAS. Big Data: What is and why it matters. Disponível em: <https://www.sas.com/pt_br/insights/big-data/what-is-big-data.html>. Acesso em: 08 de março de 2022.
- SAS. Big Data Analytics: What is and why it matters. Disponível em: <https://www.sas.com/pt_br/insights/analytics/big-data-analytics.html>. Acesso em: 09 de março de 2022.
- GOASDUFF, L.. The Best Ways to Organize Your Data Structures. Disponível em: <https://www.gartner.com/smarterwithgartner/the-best-ways-to-organize-your-data-structures>. Publicado em: 20 de junho de 2020. Acesso em: 21 de março de 2022.
- HARRAB, Y.E. How to differentiate a Data Hub, a Data Lake and a Data Warehouse. Disponível em: <https://www.semarchy.com/blog/how-to-differentiate-a-data-hub-a-data-lake-and-a-data-warehouse/>. Publicado em: 09 de março de 2020. Acesso em: 21 de março de 2022.
- ORACLE. What is Big Data?. Disponível em: <https://www.oracle.com/big-data/what-is-big-data/.> Acesso em: 08 de março de 2022.
- OREŠČANIN, D., HLUPIĆ, T. Data Lakehouse - a Novel Step in Analytics Architecture. 44th International Convention on Information, Communication and Electronic Technology (MIPRO). V. 44, P. 1242-1246. 2021.
- OUSSOUS, Ahmed et al. Big Data technologies: A survey. Journal of King Saud University - Computer and Information Sciences. V. 30, E. 4, P. 431-448. Outubro de 2018.
- SALINAS, S.O., LEMUS, A. C. N. Data Warehouse and Big Data Integration. International Journal of Computer Science & Information Technology (IJCSIT). V. 9, N.2 E. 4, P. 1-17. Abril de 2017.
- SAWADOGO, P., DARMONT, J. On data lake architectures and metadata management. Journal of Intelligent Information Systems. V. 56. P. 97-120. 2021.
Gestão de Dados
Dados precisam ser vistos como ativos críticos para o sucesso das atividades operacionais e administrativas do negócio, e não como meios temporários para alcançar resultados, ou mesmo como subprodutos de processos de negócio. Neste contexto, vale destacar que a despeito do nível de maturidade em gestão de dados de uma organização, dados e informações são vitais para as suas operações do dia-a-dia. Deste modo, independentemente se a organização consiga ou não obter valor a partir da análise de dados por meio de ferramentas de Business Intelligence, por exemplo, esta não conseguirá nem mesmo conduzir os seus negócios sem a utilização de dados (DAMA-DMBOK, 2017).
De acordo com o DAMA-DMBOK (2017), gestão de dados consiste no desenvolvimento, execução e supervisão de planos, políticas, programas e práticas que entregam, controlam, protegem e aumentam o valor dos ativos de dados e informações ao longo de seus ciclos de vida. Ainda de acordo com o DAMA-DMBOK (2017), a gestão de dados visa a utilização adequada de dados e informações para o alcance dos objetivos estratégicos da organização. Logo, um profissional de gestão de dados é qualquer pessoa que trabalha com qualquer aspecto relacionado à gestão de dados (desde o gerenciamento técnico de dados ao longo de seu ciclo de vida, até a garantia de que os dados sejam utilizados e aproveitados adequadamente) para o alcance dos objetivos estratégicos organizacionais.
Diante do exposto, pode-se concluir que as atividades de gestão de dados são muito abrangentes, incluindo atividades que vão desde a capacidade de tomar decisões consistentes sobre como obter valor estratégico a partir dos dados até as atividades técnicas de implantação e gerência de desempenho dos bancos de dados. Deste modo, pode-se afirmar que a gestão de dados requer habilidades técnicas e não técnicas (ou seja, de negócios). Portanto, a responsabilidade pela gestão de dados deve ser compartilhada entre as funções de negócios e de TI, e as pessoas em ambas as áreas devem ser capazes de colaborar para garantir que uma organização tenha dados de alta qualidade que atendam às suas necessidades estratégicas.
No intuito de prover suporte aos profissionais que atuam na gestão de dados, em 2017, a associação DAMA International (The Data Management Association) -- organização sem fins lucrativos, dedicada ao desenvolvimento de padrões internacionais para profissionais de gestão de dados -- publicou a segunda edição do livro Data Management Body of Knowledge (DMBOK). Este livro é constituído por diversos conceitos importantes sobre gestão de dados e apresenta o framework DAMA Data Management Framework, que fornece o contexto para o trabalho realizado por profissionais de gestão de dados em várias Áreas de Conhecimento. As Áreas de Conhecimento que compõem o escopo geral da gestão de dados são apresentadas pela Figura 1.
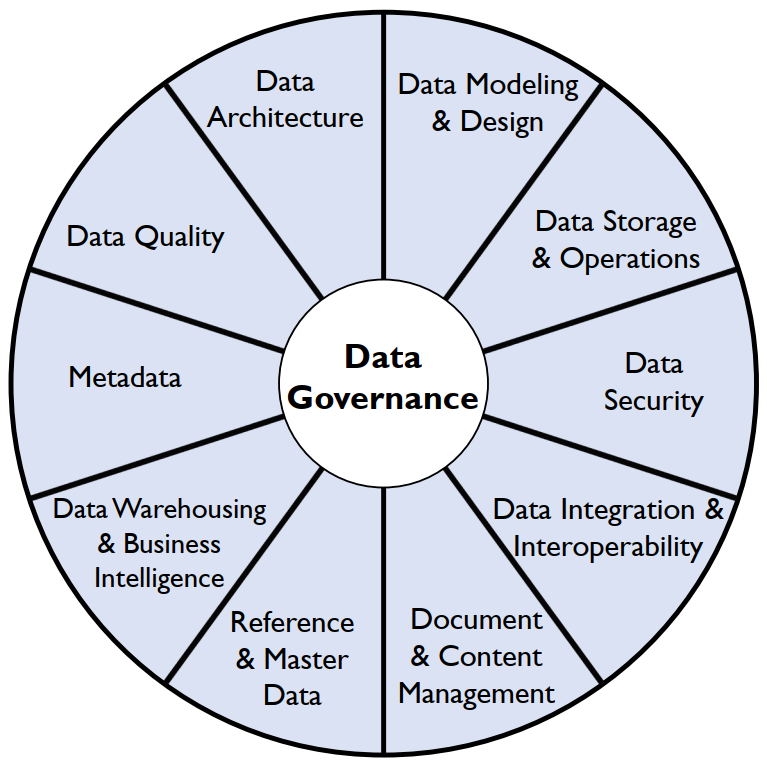
Figura 1: DAMA-DMBOK2 Data Management Framework (The DAMA Wheel) -- Framework de Gestão de Dados DAMA-DMBOK2. Fonte: (DAMA-DMBOK, 2017).
A Figura 1, apelidada pelo DAMA-DMBOK (2017) de The Dama Wheel, apresenta as Áreas de Conhecimento envolvidas na gestão de dados. A área Governança de Dados está posicionada no centro das áreas de gerenciamento de dados, uma vez que a governança é necessária para a consistência e o equilíbrio entre as demais áreas. Todas as Áreas de Conhecimento dispostas na Figura 1 são partes necessárias para uma gestão de dados madura, porém elas podem ser implementadas em momentos diferentes, a depender dos requisitos organizacionais.
O DMBOK é estruturado sobre as 11 Áreas de Conhecimento do framework de gestão de dados ilustrado pela Figura 1. Cada uma das áreas descreve o escopo e o contexto de um conjunto de atividades de gerenciamento de dados, embutindo princípios e objetivos da gestão de dados. As atividades das Áreas de Conhecimento possuem interseção tanto umas com as outras quanto com outras funções organizacionais, visto que os dados movem-se horizontalmente dentro das organizações. O DMBOK (DAMA-DMBOK, 2017) detalha, em capítulos próprios, cada uma das Áreas de Conhecimento, descritas brevemente abaixo:
- Data Governance (Governança de Dados): direciona e supervisiona o gerenciamento de dados, estabelecendo um sistema de direitos de decisão sobre os dados relevantes para as necessidades organizacionais.
- Data Architecture (Arquitetura de Dados): define o plano para o gerenciamento de ativos de dados, alinhando-se às estratégias organizacionais para o estabelecimento de requisitos estratégicos de dados e os designs para atendimento destes requisitos.
- Data Modeling and Design (Modelagem e Design de Dados): processo de descoberta, análise, representação e comunicação de requisitos de dados por meio de uma forma precisa de representação, o modelo de dados.
- Data Storage and Operations (Armazenamento de Dados e Operações): inclui o design, a implementação e o suporte ao armazenamento de dados de modo a maximizar o seu valor. Operações proveem suporte ao ciclo de vida dos dados, desde o planejamento ao descarte.
- Data Security (Segurança de Dados): assegura a manutenção da privacidade e da confidencialidade dos dados, que os mesmos não sejam violados e que sejam acessados de modo apropriado.
- Data Integration and Interoperability (Integração e Interoperabilidade de Dados): inclui processos relacionados à movimentação e consolidação de dados entre bancos de dados, sistemas e organizações.
- Document and Content Management (Gerenciamento de Documentos e Conteúdos): inclui o planejamento, a implementação e as atividades de controle utilizadas para gerenciar o ciclo de vida de dados e informações encontradas em uma variedade de mídias não estruturadas e semi-estruturadas, especialmente documentos necessários para o suporte a requisitos de conformidade legal e regulatória.
- Reference and Master Data (Dados Mestres e de Referência): inclui reconciliação e manutenção contínuas de dados críticos compartilhados entre sistemas, de modo a possibilitar que estes acessem as versões mais precisas, atualizadas e relevantes das entidades essenciais para o negócio.
- Data Warehousing and Business Intelligence (Data Warehousing e Business Intelligence): inclui os processos de planejamento, implementação e controle para o gerenciamento de tomadas de decisão orientadas a dados, permitindo que as pessoas obtenham valor a partir de dados por meio de análise e relatórios.
- Metadata (Metadados): Inclui o planejamento, a implementação e o controle das atividades necessárias para possibilitar o acesso a metadados integrados e de alta qualidade, incluindo definições, modelos, fluxos de dados e outras informações necessárias para o entendimento dos dados e dos sistemas onde os mesmos foram criados, são mantidos e acessados.
- Data Quality (Qualidade de Dados): inclui o planejamento e a implementação de técnicas de gerenciamento da qualidade para medir, avaliar e melhorar a adequação dos dados para uso organizacional.
Em complementação aos capítulos relativos às Áreas de Conhecimento, o DMBOK possui capítulos específicos para os seguintes tópicos:
- Data Handling Ethics (Ética no Tratamento de Dados): descreve o papel central que a ética de dados desempenha na tomada de decisões informadas e socialmente responsáveis, sobre os dados e suas utilizações. A conscientização sobre a ética da coleta, análise e uso de dados deve orientar todos os profissionais de gestão de dados.
- Big Data and Data Science (Big Data e Ciência de Dados): descreve as tecnologias e processos de negócios que surgem à medida que nossa capacidade de coletar e analisar grandes e diversos conjuntos de dados aumenta.
- Data Management Maturity Assessment (Avaliação da Maturidade na Gestão de Dados): descreve uma abordagem para avaliar e melhorar a capacidade de gestão de dados de uma organização.
- Data Management Organization and Role Expectations (Organização da Gestão de Dados e Expectativas de Papéis): fornece as melhores práticas e considerações para organizar as equipes de gestão de dados e permitir práticas de gestão de dados bem-sucedidas.
- Data Management and Organizational Change Management (Gestão de Dados e Gerenciamento de Mudanças Organizacionais): descreve como planejar e lidar com as mudanças culturais, necessárias para incorporar práticas eficazes de gestão de dados na organização.
Governança de Dados
O DMBOK (DAMA-DMBOK, 2017) define Governança de Dados (GD) como a execução de autoridade, controle e tomada de decisão compartilhada (planejamento, monitoramento e fiscalização) sobre o gerenciamento de ativos de dados, com os seguintes objetivos:
- Possibilitar que uma organização gerencie seus dados como um ativo;
- Definir, aprovar, comunicar e implementar princípios, políticas, procedimentos, métricas, ferramentas e responsabilidades no gerenciamento de dados;
- Monitorar e orientar sobre a conformidade com as políticas, quanto ao uso de dados e quanto às atividades de gerenciamento de dados.
Neste mesmo sentido, Barbieri (2019) define Governança de Dados como um conjunto de práticas, dispostas em um framework, com o objetivo de organizar o uso e o controle adequado dos dados como um ativo organizacional.
O DAMA-DMBOK (2017) afirma que dados e informações são ativos, visto que são ou podem criar valor para a organização. No entanto, ao mesmo tempo que podem cirar valor, trazem riscos (vazamentos de dados, tomadas de decisões erradas devido a problemas de interpretação ou inconsistências, etc.). O DAMA-DMBOK (2017) complementa que governar dados exige um programa contínuo focado em assegurar que a organização obtenha valor a partir dos seus dados, minimizando os riscos associados aos mesmos. Neste sentido, a Governança de Dados fornece princípios, políticas, procedimentos, estrutura operacional, métricas e vigilância.
A Governança de Dados fornece a orientação e o contexto de negócios necessários para que as atividades de gerenciamento de dados estejam alinhadas com os objetivos organizacionais, de modo que a organização obtenha valor a partir dos seus dados.
Relação entre Governanças
A Governança de Dados surgiu a partir do termo raiz “Governança”, extraído do contexto maior “Governança Corporativa”. A Governança de Dados tangencia pontos da Governança de TI, focando em princípios de organização e controle sobre os insumos de dados, essenciais para a produção de informação e conhecimento (BARBIERI, 2019).
De acordo com Barbieri (2019), os dados não podem mais ficar restritos à esfera da tecnologia da informação, mas sim, devem ser considerados insumos de negócio, um ativo organizacional. Para tal, as organizações devem definir objetivos organizacionais e processos institucionalizados, que devem ser implementados dentro de um equilíbrio fundamental entre tecnologia da informação e área de negócios. A Figura 1 ilustra as relações entre Governança Corporativa, Governança de Dados e Governança de TI.
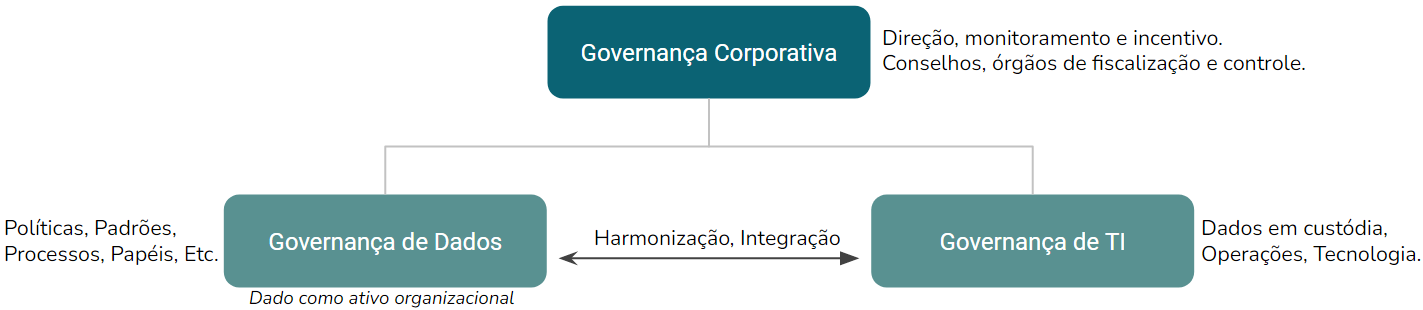
Figura 1: Relações entre Governança Corporativa, Governança de Dados e Governança de TI. Fonte: Adaptado de BARBIERI (2019).
Frameworks para Definição dos Componentes da Governança de Dados
Alguns frameworks sugerem o conceito e a forma de implementação da Governança de Dados em uma organização. Barbieri (2019) destaca os seguintes: (a) Framework de Governança de Dados - 5W2H; (b) Framework de Governança de Dados - IBM; (c) EDM (Enterprise Data Management Council) e DCAM (Data Management Capacity Assessment Model); (d) Modelo Data Management Maturity (DMM) do CMMI institute; e (f) Gestão, Governança e Gerência de Dados: DAMA DMBOk V2.
Segundo Barbieri (2019), todos os frameworks supracitados mostram alguns caminhos comuns, mas, o DAMA DMBOK V2 mostra-se acima dos demais. Sendo, portanto, a referência mais indicada na implementação e execução de programas de gestão e Governança de Dados.
Foco e Escopo
O foco e o escopo de um programa de GD depende das necessidades de cada organização, mas a maioria dos programas incluem (DAMA-DMBOK, 2017):
- Estratégias: Definindo, comunicando e conduzindo a execução da Estratégia de Dados e Estratégia de Governança de Dados;
- Políticas: Definindo e aplicando políticas relacionadas ao gerenciamento, acesso, uso, segurança e qualidade de dados e metadados;
- Padrões e qualidade: Definindo e aplicando padrões de qualidade e arquitetura de dados;
- Supervisão: Provendo meios para monitoramento, auditoria e correção nas principais áreas de qualidade, política e curadoria de dados;
- Conformidade: Assegurando que a organização possa alcançar requisitos de conformidade regulatória (compliance) relacionados a dados;
- Gerenciamento de dúvidas e problemas: Identificando, definindo, escalando e resolvendo problemas e dúvidas relacionados à segurança de dados, acesso a dados, qualidade de dados, conformidade regulatória, propriedade de dados, política, padrões, terminologia ou procedimentos de governança de dados;
- Gerenciamento de projetos de dados: Patrocinando os esforços para melhoria das práticas de gerenciamento de dados;
- Valoração de ativos de dados: Definindo padrões e processos para definição consistente de valor comercial para ativos de dados.
Para comprir tais objetivos, um programa de Governança de Dados precisará desenvolver políticas e procedimentos, cultivar práticas de curadoria de dados (stewardship) em diferentes níveis da organização, e envolver-se em esforços de gerenciamento de mudanças organizacionais que comunicam ativamente à organização os benefícios da GD aprimorada e os comportamentos necessários para gerenciar, com sucesso, os dados como um ativo.
É importante destacar que a Governança de Dados não é um fim em si mesma. Ela precisa alinhar-se diretamente às estratégias organizacionais. Quanto mais claramente a GD auxiliar na resolução dos problemas organizacionais, maior a probabilidade das pessoas mudarem comportamentos e adotarem práticas de governança.
Assim como um auditor controla processos financeiros mas não executa a gestão financeira, a Governança de Dados deve garantir que os dados sejam gerenciados adequadamente sem executar diretamente o gerenciamento (Figura 2). Deste modo, a Governança de Dados representa uma separação inerente de dever entre a supervisão e a execução.
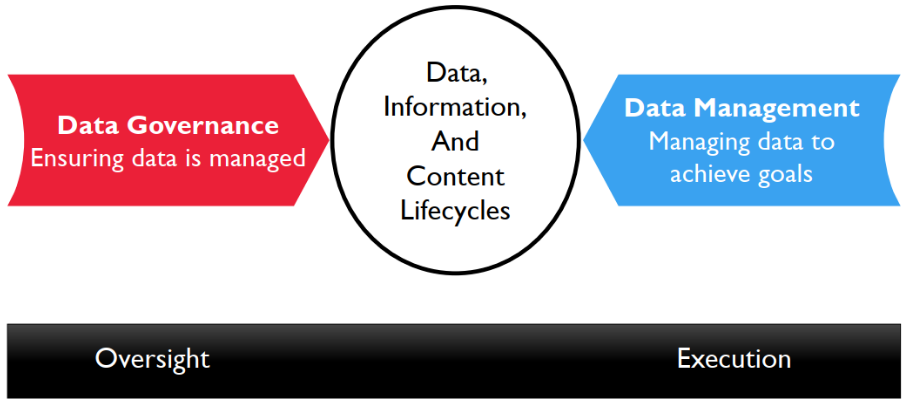 Figura 2: Governança de Dados e Gerenciamento de Dados. Fonte: (DAMA-DMBOK, 2017)
Figura 2: Governança de Dados e Gerenciamento de Dados. Fonte: (DAMA-DMBOK, 2017)
No framework de Gestão de Dados DAMA-DMBOK2 (Figura 3), a Governança de Dados está posicionada no centro das demais Áreas de Conhecimento, trazendo consistência e equilíbrio entre as áreas por meio do supervisionamento e do direcionamento das atividades de gerenciamento de dados. Deste modo, a responsabilidade sobre a GD é compartilhada entre os curadores de dados de negócio (business data stewards) e a área técnica de gerenciamento de dados (DAMA-DMBOK, 2017).
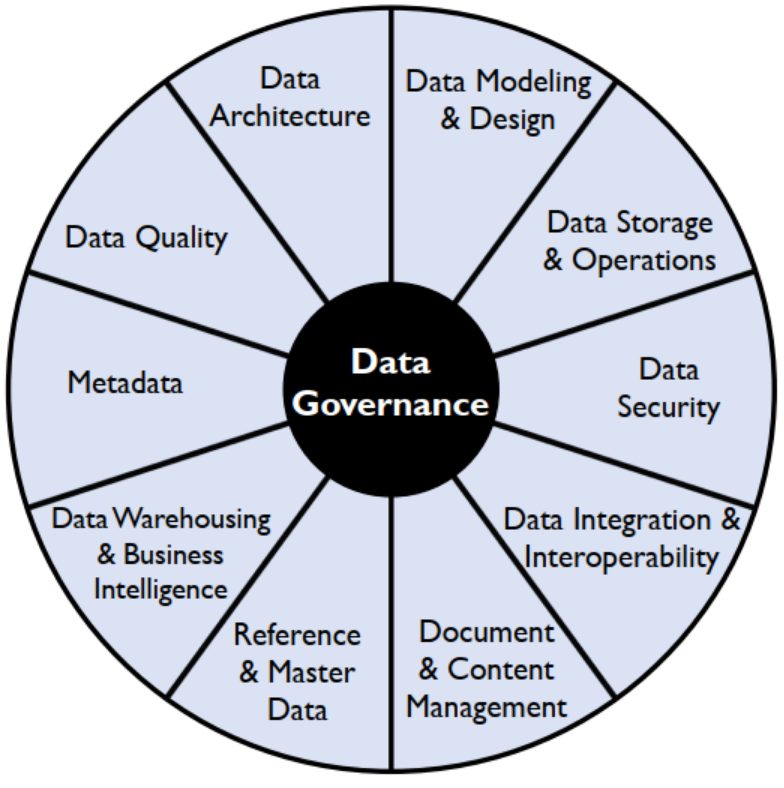
Figura 3: DAMA-DMBOK2 Data Management Framework (The DAMA Wheel) -- Framework de Gestão de Dados DAMA-DMBOK2. Fonte: (DAMA-DMBOK, 2017).
A Governança de Dados, além de ser uma área de conhecimento, reside também dentro de cada outra área de conhecimento, com olhar específico de controle sobre aquela gerência. Por exemplo, dentro da área de conhecimento Integração e Interoperabilidade de Dados (Data Integration & Interoperability), a Governança de Dados deverá estender sua visão para acordos de compartilhamento de dados, linhagem de dados e métricas de integração (BARBIERI, 2019).
Cultura Organizacional
As organizações se esforçam cada vez mais para tornarem-se orientadas por dados (data-driven), considerando proativamente os requisitos de dados como parte do desenvolvimento de estratégias, planejamento de programas e implementação de tecnologias. No entanto, fazer isso muitas vezes envolve desafios culturais significativos. Conforme afirmado no DAMA-DMBOK (2017), a cultura de uma organização pode inviabilizar qualquer estratégia de dados. Deste modo, os esforços de Governança de Dados precisam incluir um componente de mudança cultural, apoiado por uma liderança forte.
Neste sentido, o DAMA-DMBOK (2017) afirma que, para a maioria das organizações, a mudança cultural é o maior desafio para o sucesso de programas de gestão e governança de dados. Considerando que um dos princípios fundamentais da gestão de mudanças é que a mudança organizacional exige mudança individual, e que programas de gestão e governança de dados exigem mudança cultural, o gerenciamento formal de mudanças torna-se necessário para o sucesso destes programas.
Ferramentas
O DAMA-DMBOK (2017) afirma que a Governança de Dados é fundamentalmente sobre o comportamento organizacional. Ou seja, este não é um problema que pode ser solucionado apenas com tecnologia. Deste modo, antes de escolher uma ferramenta para uma função específica, como por exemplo uma solução tecnológica para gerenciamento do glossário de negócios -- ferramenta central na Governança de Dados --, a organização precisa definir suas metas e requisitos gerais de governança, com o objetivo de estabelecer o seu conjunto de ferramentas. Estas ferramentas devem ser avaliadas em suas capacidades e funcionalidades, no intuito de evitar sobreposição indesejada de funcionalidades e recursos. Algo que pode trazer desorganização e interferir negativamente no processo de implantação do programa de GD.
Implementação e Estabelecimento
De acordo com Barbieri (2019), uma das principais ações para a implementação da Governança de Dados constitui a definição formal de uma estrutura corporativa, composta por elementos de negócios e de TI, regida por políticas amplas de dados. Deve-se buscar constantemente a conscientização organizacional de que dados não devem mais ser vistos como produtos colaterais da execução de processos.
O processo de implementação da Governança de Dados não é trivial, diante disso, Barbieri (2019) sugere buscar modificações culturais gradativas, de modo a alcançar patamares crescentes de maturidade. Uma das formas mais comuns de adoção da GD é por meio de projetos especiais de dados (projeto estruturante, de extrema importância organizacional). Projetos de Business Intelligence, de qualidade, Gerência de Dados Mestres e LGPD estão entre os tipos mais usuais de projetos com esta finalidade. Tais projetos, cada vez mais, percebem que de nada adianta o investimento em novas plataformas de dados, caso estes não estejam devidamente “governandos”.
Neste mesmo sentido, o DAMA-DMBOK (2017) afirma que a Governança de Dados deve ser implementada de modo incremental, dentro de um contexto estratégico maior de negócios e gestão de dados. Portanto, os objetivos globais devem ser mantidos em evidência enquanto as peças da GD são colocadas no lugar.
Barbieri (2019) salienta que dados "governados" não significa apenas a resolução física de duplicatas ou de conflitos de hierarquias semânticas, por exemplo, mas também a definição clara dos papéis de curadores de dados (data stewards) e de responsáveis pelos dados (data owners), que serão as referências responsáveis por aquele ativo específico dentro do contexto organizacional. Tudo isso orientado por políticas, padrões e processos, definidos e aprovados sob uma estrutura de governança.
Glossário de Negócios
Um glossário de negócios é um tipo de dicionário que busca garantir coerência e consistência semântica na organização, contendo termos e definições padronizados e organizados, relativos aos dados geridos na organização. É uma ferramenta central na Governança de Dados (DAMA-DMBOK, 2017).
O desenvolvimento de uma documentação padronizada para os dados reduz a ambiguidade e melhora a comunicação. Para tanto, as definições devem ser claras, rigorosas, e explicar quaisquer exceções, sinônimos e variações.
De acordo com o DAMA-DMBOK (2017), um glossário é necessário pois as pessoas utilizam palavras de forma diferente. Sendo particularmente importante que dados possuam definições claras, pois estes representam coisas além dele mesmo. Pode-se adicionar que muitas organizações desenvolvem o seu próprio vocabulário, podendo ressignificar conceitos utilizados em outras áreas e organizações.
Ainda de acordo com o DAMA-DMBOK (2017), um glossário de negócios não deve ser meramente uma lista de termos e definições. Cada termo deve ser associado, quando aplicável, a metadados importantes para a sua compreensão e manutenção, tais como: sinônimos, exceções, métricas, área responsável, etc.
Um glossário de negócios possui os seguintes objetivos (DAMA-DMBOK, 2017):
- Reduzir a ambiguidade e padronizar o entendimento de conceitos e terminologias na organização;
- Reduzir os riscos de uso indevido de dados devido à compreensão inadequada dos conceitos do negócio;
- Melhorar o alinhamento entre os ativos de tecnologia e a área de negócios.
O Glossário de Negócios da UFLA pode ser acessado a partir da seguinte URL: https://glossario.ufla.br/.
Gerência de Dados Mestres e de Referência
Em qualquer organização, certos dados são comuns entre diferentes áreas de negócio, processos e sistemas. O compartilhamento de dados comuns (ex: lista de servidores; lista de alunos; lista de cursos; centros de custo; códigos de localização geográfica; etc) dentre as unidades de negócio é algo que beneficia tanto a organização quanto os seus clientes, visto que minimiza os riscos de inconsistências. Usuários de dados geralmente assumem a existência de um certo nível de consistência, até que se deparam com divergências entre fontes distintas (DAMA-DMBOK, 2017).
Na maioria das organizações, os sistemas evoluem de forma mais orgânica do que os profissionais de gerenciamento de dados gostariam. Particularmente em grandes organizações, vários projetos e iniciativas, fusões e aquisições e outras atividades de negócios resultam em vários sistemas executando essencialmente as mesmas funções, isolados uns dos outros. Essas condições inevitavelmente levam a inconsistências na estrutura de dados e valores de dados entre sistemas. Essa variabilidade aumenta os custos e os riscos, que podem ser reduzidos através da Gerência de Dados Mestres e Dados de Referência (DAMA-DMBOK, 2017).
Dados de Referência
Dados de Referência, ou Dados Referenciais, são qualquer dado utilizado para caracterizar ou classificar outro dado, ou para relacionar dados com informações externas à organização. Os Dados de Referência mais básicos consistem em códigos e descrições, mas alguns podem ser mais complexos e incorporar mapeamentos e hierarquias. Dados de referência existem em praticamente todos os armazenamentos de dados. Classificações e categorias podem incluir status ou tipos (por exemplo, Status do pedido: Novo, Em andamento, Fechado, Cancelado) (DAMA-DMBOK, 2017).
De acordo com Barbieri (2019), Dados Referenciais são atributos, normalmente associados aos Dados Mestres e que merecem pela sua volatilidade uma certa gerência especial. Por exemplo: CEP (atributo de endereço de alguém ou de alguma coisa), Código Internacional de Doenças (atributo fundamental do Dado Mestre Doenças em um ambiente de sistemas de saúde, por exemplo). São normalmente obtidos de fontes externas definidas por entidades oficiais (CID, CEP, código de aeroportos, códigos de cidades, de estados, de países, etc.), mas podem ser produzidos internamente, de acordo com o negócio da empresa/organização. Têm forte associação com os Dados Mestres, na maioria das vezes, codificando algumas de suas propriedades.
Dados de Referência e Dados Mestre compartilham propósitos conceitualmente semelhantes. Ambos fornecem contexto para a criação e uso de dados transacionais (Dados de Referência também fornecem contexto para Dados Mestres). Eles permitem que os dados sejam compreendidos de forma significativa.
O objetivo da Gerência de Dados de Referência (Reference Data Management - RDM) é garantir que os Dados de Referência sejam consistentes e atuais em diferentes funções e que os dados sejam acessíveis à toda a organização.
Dados Mestres
Segundo a definição do Gartner (2022), Dados Mestres pode ser definido como um conjunto consistente e uniforme de identificadores e atributos que descrevem as principais entidades da organização, como por exemplo: alunos, cursos, colaboradores, estrutura administrativa, fornecedores, hierarquias, planos de conta, etc.
De acordo com Barbieri (2019) Dados Mestres são os dados base ou pilares da instituição. Os Dados Mestres tendem a ser mais estáveis e não muito relacionados com o tempo e sustentam as grandes transações institucionais. São chamados dados de fundação (foundational) e através deles são produzidos os dados transacionais. Por exemplo, um cliente do WalMart compra produtos em uma loja. Veja que há três dados mestres (produto, loja e cliente) se relacionando em um ato de Compra, que é um dado transacional.
Dados Mestres exigem a identificação e/ou desenvolvimento de uma versão confiável da verdade para cada instância de entidade conceitual, como aluno, curso, unidade organizacional, pessoa ou organização, e a manutenção da validade dessa versão. O principal desafio é a resolução de entidade, o processo de discernir e gerenciar associações entre dados de diferentes sistemas e processos.
A Gerência de Dados Mestres (Master Data Management - MDM) reduz os riscos de tomada de decisão incorreta e perda de oportunidades por meio de uma representação consistente das entidades críticas para o negócio da organização (DAMA-DMBOK, 2017).
Gerência de Dados Mestres
A Gerência de Dados Mestres (Master Data Management - MDM) envolve o controle sobre valores e identificadores de Dados Mestres de modo a permitir o uso consistente entre os sistemas, dos dados mais precisos e atualizados sobre as entidades essenciais para o negócio (DAMA-DMBOK, 2017).
De acordo com o Gartner (2022), Gerência de Dados Mestres é uma disciplina na qual a área de negócios e a área de TI trabalham juntas para garantir uniformidade, precisão, curadoria (stewardship), consistência semântica e responsabilidade (accountability) dos ativos de Dados Mestres compartilhados da organização.
DAMA (2017) menciona que, infelizmente, o acrônimo MDM é muitas vezes referenciado como sistemas ou produtos utilizados para gerenciar Dados Mestres. Embora existam aplicações que facilitem esta gerência, elas não garantem que os Dados Mestres serão gerenciados de modo a atender as necessidades organizacionais.
A avaliação dos requisitos de MDM de uma organização inclui identificar DAMA-DMBOK (2017) :
- Quais funções, organizações, lugares e coisas são referenciadas repetidamente;
- Quais dados são usados para descrever pessoas, organizações, lugares e coisas;
- Como os dados são definidos e estruturados, incluindo a sua granularidade;
- Onde os dados são criados/originados, armazenados, disponibilizados e acessados;
- Como os dados mudam à medida que se movem pelos sistemas dentro da organização;
- Quem usa os dados e para que finalidades;
- Quais critérios são usados para entender a qualidade e confiabilidade dos dados e suas fontes.
DAMA-DMBOK (2017) complementa que a Gerência de Dados Mestres é desafiadora, e ilustra um desafio fundamental: “as pessoas escolhem maneiras diferentes de representar conceitos semelhantes e a reconciliação entre essas representações nem sempre é direta; tão importante quanto, as informações mudam ao longo do tempo e contabilizar sistematicamente essas mudanças requer planejamento, conhecimento sobre os dados e habilidades técnicas. Resumindo, é muito trabalhoso.“
Uma organização que percebe a necessidade da Gerência de Dados Mestres provavelmente já possui um arcabouço complexo de sistemas, com múltiplas formas de captura e armazenamento de dados que representam entidades do mundo real. Devido ao crescimento orgânico ao longo do tempo, ou fusões e aquisições, os sistemas que forneceram entrada para o processo de MDM podem ter definições diferentes das próprias entidades e muito provavelmente possuem padrões diferentes sobre a definição de qualidade de dados. Devido a essa complexidade, é recomendado abordar a Gerência de Dados Mestres um domínio de negócios por vez. Ou seja, comece com algumas entidades e atributos e evolua com o tempo, de modo incremental.
Dentre as atividades críticas para o sucesso da Gerência de Dados Mestres mencionadas por DAMA-DMBOK (2017), destaco:
- Reconciliar e consolidar dados entre fontes para fornecer um registro mestre ou a melhor versão da verdade.
- Provisionamento de acesso a dados confiáveis entre os sistemas, seja por meio de leituras diretas, serviços de dados, Data Warehouses e outros meios de armazenamento analítico.
- Impor o uso de Dados Mestres dentro da organização. Esse processo requer governança e gerenciamento de mudanças para garantir uma perspectiva corporativa compartilhada.
A Figura 1 apresenta as principais etapas de processamento necessárias para a Gerência de Dados Mestres (MDM). Inclui as etapas de gerência do modelo de dados; aquisição de dados; validação padronização e enriquecimento de dados; resolução de entidades; e administração e compartilhamento de dados. Em um ambiente abrangente de MDM, o modelo de dados lógicos será instanciado fisicamente em várias plataformas. Este modelo orienta a implementação da solução de MDM, fornecendo a base para os serviços de integração.
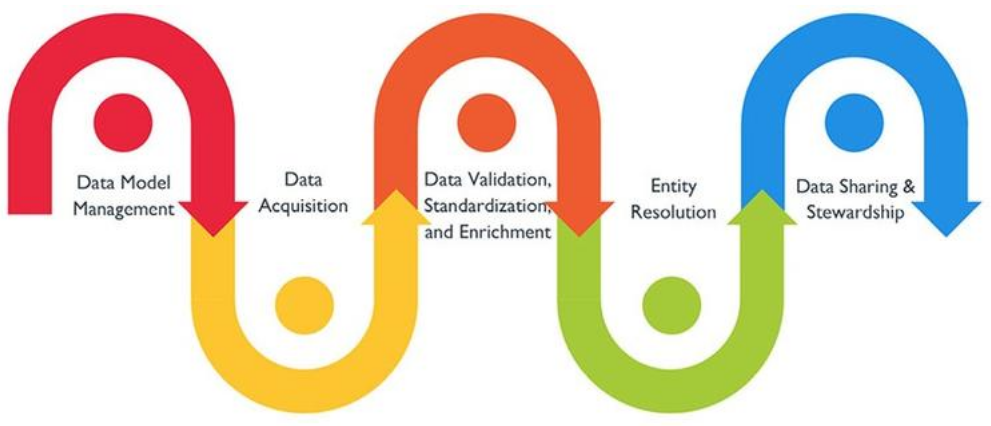
Figura 1: Processos-chave de etapas para a Gerência de Dados Mestres. Fonte: DAMA-DMBOK (2017)
Note que as etapas da Figura 1 são condizentes com as etapas que ocorrem em uma solução de Data Warehouse / Business Intelligence, da modelagem ao compartilhamento e visualização de dados.
Sistema de Registro e Sistema de Referência
Quando existem versões potencialmente diferentes da “verdade”, é necessário distingui-las. Para isso, é preciso saber de onde os dados se originam ou são acessados e quais dados foram preparados para usos específicos. Um Sistema de Registro é um sistema onde os dados são criados/capturados e/ou mantidos por meio de um conjunto definido de regras (por exemplo, um sistema ERP pode ser o Sistema de Registro para clientes de venda). Um Sistema de Referência é um sistema onde os consumidores de dados podem obter dados confiáveis para apoiar transações e análises, mesmo que a informação não tenha origem no sistema de referência. Sistemas MDM, Data Hubs e Data Warehouses geralmente servem como sistemas de referência (DAMA-DMBOK, 2017).
Fonte confiável
Uma fonte confiável (Trusted Source) pode ser definida como uma fonte com “a versão mais precisa da verdade”, baseada na combinação de regras automatizadas e gerência manual (curadoria) do conteúdo dos dados. Todo sistema de MDM/RDM deve ser gerido para ser esta fonte confiável institucional (DAMA-DMBOK, 2017).
Business Intelligence
Business Intelligence (BI), ou Inteligência de Negócios é um termo abrangente que pode ser definido como um conjunto de sistemas e processos que uma organização utiliza para recuperar, processar e analisar informações para suporte à tomada de decisão (KIMBALL e ROSS, 2013).
De acordo com a Microsoft (2022), soluções de BI auxiliam organizações na análise de dados históricos e correntes, de modo a possibilitar a descoberta de insights acionáveis para a tomada de decisão estratégica. Ainda segundo a Microsoft (2022), ferramentas de BI tornam isso possível devido ao processamento de conjuntos de dados provenientes de múltiplas fontes, apresentando as descobertas em formatos visuais fáceis de entender e compartilhar.
Neste mesmo sentido, Tableau (2022) afirma que BI combina análise de negócios (business analytics), mineração de dados, visualização de dados, ferramentas e infraestrutura de dados e práticas recomendadas para ajudar as organizações a tomar decisões impulsionadas por dados.
Ainda no contexto de BI, Gartner (2022) afirma que Plataformas de BI habilitam organizações a construírem aplicações de BI por meio do provimento de capacidades em três categorias: análises, como por exemplo Online Analytical Processing (OLAP); entrega de informações, como relatórios e dashboards; e integração de plataforma, como a gestão de metadados de BI e um ambiente de desenvolvimento.
De acordo com as definições apresentadas, pode-se observar que o termo BI é abrangente, podendo abarcar diferentes tipos de iniciativas, das mais simples, como por exemplo a utilização de ferramentas de visualização de dados e planilhas eletrônicas para extrair e analisar dados armazenados em sistemas transacionais ou em planilhas, às mais complexas, que podem envolver a construção de Data Warehouses, Data Marts e Data Lakes.
De acordo com Kimball e Ross (2013), a construção de um Data Warehouse capaz de integrar toda a instituição é fundamental para a governança de dados. A ausência de um DW institucional como plataforma de BI, alinhado à uma boa governança de dados, leva à perpetuação de silos de dados similares entre departamentos, mas com versões da verdade ligeiramente diferentes (KIMBALL e ROSS, 2013).
Data Warehouse
Data Warehouse (DW) consiste em um sistema para armazenamento de dados originados de múltiplas fontes, especialmente estruturados para consulta e análise. Um DW busca a criação de uma fonte de dados padronizada, confiável e de acesso simplificado, para apoio à tomada de decisão (Kimball e Ross, 2013).
De acordo com o DAMA (2017), um DW é a combinação de dois componentes principais: (a) um banco de dados integrado para apoio à tomada de decisão e (b) o conjunto de softwares relacionados, utilizados para coletar, limpar, transformar e armazenar os dados a partir de várias fontes de origem.
De acordo com Anand (2019), Data Warehouse pode ser considerado um modelo arquitetônico para armazenamento de dados estruturados. Não sendo portanto uma tecnologia em especial.
Segundo Inmon (2005), um DW consiste em uma coleção de dados orientados por assunto, integrados, não voláteis e variantes no tempo, com o intuito de prover suporte à tomada de decisão. Na arquitetura de DW proposta por Inmon (2005), a não volatilidade de um DW deve ser garantida por meio do que é chamado pelo autor de snapshots. De acordo com Inmon (2005), uma vez inserido em um DW, o dado não poderá mais ser atualizado. No entanto, em seu próprio livro, são demonstradas algumas opções de alteração de dados históricos, como por exemplo, a correção de um valor incorrento de saldo bancário histórico de cliente. Este aspecto de não volatilidade absoluta conflita com a proposta de arquitetura de Data Warehouse de Kimball e Ross (2013). Na aquitetura de Kimball e Ross (2013), a manutenção da história em um DW é feita por meio da técnica Slowly Changing Dimensios (SCDs). Esta técnica assume a possibilidade de modificação de dados históricos em um modelo dimensional, possibilitando este controle a nível de atributos.
De acordo com Khine e Wang (2018), um Data Warehouse ser não volátil significa que os dados permanecem inalterados entre as cargas de dados. Diferenciando-se dos dados transacionais de sistemas que podem ser alterados a todo instante.
Existem diversas abordagens para a construção de Data Warehouses. Kimball e Ross (2013) propõem uma abordagem de construção de um DW que integre toda a organização (Enterprise Data Warehouse - EDW). De acordo com os autores, a construção deste tipo de DW é fundamental para a governança de dados. Ainda de acordo com Kimball e Ross (2013), a ausência de um DW institucional como plataforma de BI, alinhado à uma boa governança de dados, leva à perpetuação de silos de dados similares entre departamentos, mas com versões da verdade ligeiramente diferentes.
A UFLA utiliza a arquitetura de Enterprise Data Warehouse proposta por Kimball e Ross (2013). Esta escolha deve-se ao fato desta ser uma arquitetura já consolidada, amplamente aceita e utilizada no mercado.
O EDW é construído com a técnica denominada Modelagem Dimensional, que, segundo Kimball e Ross (2013), trata-se de uma abordagem amplamente aceita para consolidação de dados analíticos por abordar dois requisitos de forma simultânea:
-
- Apresenta dados em formatos entendíveis por usuários de negócio;
- Organiza os dados de modo a otimizar o desempenho de consulta.
Kimball e Ross (2013) mencionam ainda as seguintes técnicas existentes para a construção de Data Warehouses:
-
- Independent Data Mart Architecture;
- Hub-and-Spoke Corporate Information Factory Inmon Architecture;
- Hybrid Hub-and-Spoke and Kimball Architecture.
Kimball e Ross (2013) demonstram que as abordagens mencionadas acima possuem grandes desvantagens em comparação à abordagem de EDW com Modelagem Dimensional. Para mais detalhes sobre essas desvantagens consulte as páginas 26, 27, 28, 29 e 30 (KIMBALL e ROSS, 2013).
Um EDW considera os seguintes princípios para a sua construção:
-
- Utiliza Modelagem Dimensional do tipo Star Schema;
- Armazena dados na menor granularidade possível (embora possa também armazenar agrupamentos e sumarizações, realizadas a partir dos dados granulares);
- Os fatos são orientados a processos de negócio, e não a setores ou departamentos específicos;
- Utiliza Dimensões Coformadas.
A Figura abaixo apresenta os elementos chave para a arquitetura Kimball de DW/BI (KIMBALL e ROSS, 2013):
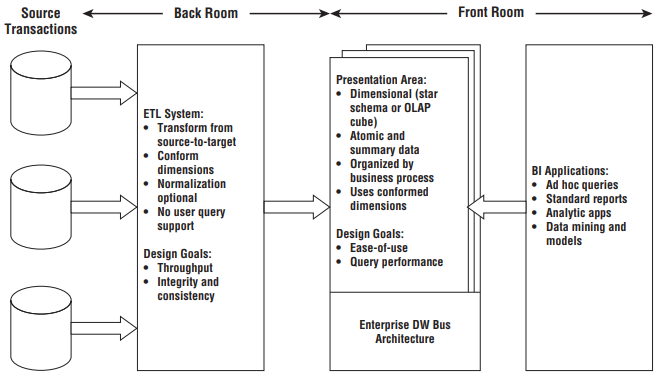
De acordo com Khine e Wang (2018), como um Data Warehouse possui uma estrutura fixa, com processos de extração, transformação e carga de dados muito bem definidos, este possui um aspecto forte de gestão de governança de dados.
Data Warehousing
De acordo com o DAMA (2017), Data Warehousing refere-se aos processos operacionais de extração, limpeza, transformação, controle e carregamento que mantêm os dados em um Data Warehouse. O processo de Data Warehousing concentra-se em possibilitar a manutenção de um histórico de contexto de negócios, por meio da aplicação de regras de negócios e manutenção dos relacionamentos apropriados dos dados de negócio. O processo de Data Warehousing ainda inclui atividades para gestão de repositórios de metadados.
Ainda de acorodo com o DAMA (2017), tradicionalmente, Data Warehousing concentra-se em dados estruturados. No entanto, com os recentes avanços tecnológicos, o espaço de BI e DW agora também abrange dados semiestruturados e não estruturados.
Data Mart
Um Data Mart é um subconjunto completo de um Data Warehouse, e, assim como este, deve possuir os dados armazenados em seu formato mais granular (KIMBALL e ROSS, 2010).
Data Marts são muitas vezes construídos devido à impossibilidade de se construir de uma única vez, um Data Warehouse (DW) capaz de atender a toda a organização (Kimball e Ross, 2010). Como demonstrado por Kimball e Ross (2013), uma arquitetura de barramento (Enterprise Data Warehouse Bus Architecture) permite a construção incremental de DW que atenda a toda a organização (Enterprise Data Warehouse - EDW).
Embora possa-se buscar a construção de um EDW a partir de um conjunto de Data Marts, por meio da utilização da Modelagem Dimensional e dimensões conformadas (cópias fiéis e atualizadas de dimensões comuns) entre os diferentes Data Marts, esta arquitetura não estará totalmente de acordo com o conceito de EDW de Kimball e Ross (2013), devido a um dos princípios centrais desta arquitetura: a construção do EDW deve ser orientada a processos de negócio, não a departamentos ou setores.
Big Data
De acordo com Salinas e Lemus (2017), o termo Big Data foi criado em 1997 por Michael Cox e David Ellsworth, pesquisadores da NASA que tinham que trabalhar com conjuntos de dados geralmente muito grandes, o que sobrecarregava a memória principal, disco local e capacidade de disco remoto. Eles chamaram isso de problema do Big Data.
Apesar de ser amplamente referenciado, Big Data não tem uma definição rigorosa e consensual. Geralmente está associado ao tratamento de dados massivos, extraídos de diferentes fontes e sem estruturas pré-definidas (SALINAS e LEMUS, 2017). De acordo com Gandomi e Haider (2015), cerca de 95% dos dados tratados por tecnologias de Big Data são dados não estruturados.
Para alguns autores, Big Data nada mais é do que um conjunto de dados cujo tamanho está além das ferramentas típicas de bancos de dados para capturar, armazenar, gerenciar e analisar (SALINAS e LEMUS, 2017). De acordo com SAS (2022), big data refere-se a conjuntos de dados tão grandes, rápidos ou complexos que são difíceis ou impossíveis de processar usando métodos tradicionais. O ato de acessar e armazenar grandes quantidades de informações para análise existe há muito tempo. Mas o conceito de big data ganhou força no início dos anos 2000.
Para Anand (2019), Big data é uma tecnologia utilizada para armazenar dados, tanto em formatos não estruturados quanto semi estruturados e estruturados, utilizando dispositivos de armazenamento mais baratos. Para agilizar o processamento, este é feito de forma descentralizada e distribuída por múltiplos servidores. Os dados são armazenados em formato nativo, sem um esquema ou modelagem definida.
Segundo Oussous et al. (2018) o termo big data refere-se a grandes conjuntos de dados, em constante crescimento, que incluem formatos heterogêneos de dados estruturados, não estruturados e semiestruturados. Big data possui natureza complexa e exige tecnologias sofisticadas e algoritmos avançados. Neste novo contexto, ferramentas tradicionais de Business Intelligence mostram-se ineficientes para aplicações de big data.
Muitos experts e cientistas de dados definem big data pelas seguintes características principais (chamadas 3 Vs) (OUSSOUS et al., 2018) (GANDOMI e HAIDER, 2015):
- Volume: grandes volumes de dados são gerados continuamente a partir de milhares de dispositivos e aplicações (smartphones, redes sociais, sensores, logs, etc.);
- Velocidade: Dados são gerados de modo rápido e precisam ser processados rapidamente para que insights relevantes sejam extraídos;
- Variedade: big data é gerado a partir de várias fontes e em múltiplos formatos (por exemplo: documentos, vídeos, comentários, logs, etc.). Grandes conjuntos de dados são constituídos por dados estruturados e não estruturados, públicos ou privados, de origem local ou distante, compartilhados ou confidenciais, completos ou incompletos, etc.
De acordo com Gandomi e haider (2015), além dos três Vs principais, as seguintes novas dimensões foram também mencionadas como características inerentes ao Big Data:
- Veracidade: característica definida pela IBM que representa a falta de confiabilidade inerente a algumas fontes de dados. Por exemplo, os sentimentos dos clientes nas mídias sociais são de natureza incerta, pois envolvem julgamento humano. No entanto, eles contêm informações valiosas. Assim, a necessidade de lidar com dados imprecisos e incertos é outra faceta do big data, que é abordada usando ferramentas e análises desenvolvidas para gerenciamento e mineração de dados incertos;
- Variabilidade (e complexidade): novas características apresentadas pelo SAS. A variabilidade refere-se à variação nas taxas de fluxo de dados. Muitas vezes, a velocidade do big data não é consistente e tem picos e vales periódicos. Complexidade refere-se ao fato de que big data é gerado por meio de uma infinidade de fontes. Isso impõe um desafio crítico: a necessidade de conectar, combinar, limpar e transformar dados recebidos de diferentes fontes;
- Valor: a Oracle introduziu o Valor como um atributo definidor de big data. Com base na definição da Oracle, big data geralmente é caracterizado por uma “baixa densidade de valor”. Ou seja, os dados recebidos na forma original costumam ter um valor baixo em relação ao seu volume. No entanto, um valor alto pode ser obtido analisando grandes volumes desses dados.
Desafios
Embora a mineração de big data ofereça oportunidades atrativas, pesquisadores e profissionais têm se deparado com diversos desafios ao tentarem extrair valor e conhecimento a partir desta mina de informações. As dificuldades estão em diferentes níveis, incluindo: captura de dados, armazenamento, busca, compartilhamento, análise, gerenciamento e visualização. Além disso, há problemas de segurança e privacidade, especialmente em aplicativos orientados a dados distribuídos (OUSSOUS et al., 2018).
Apesar de novas tecnologias terem sido desenvolvidas para o armazenamento de dados, os volumes de dados estão dobrando em tamanho a cada dois anos. As empresas ainda se esforçam para acompanhar a evolução de seus dados e encontrar maneiras de armazená-los com eficiência (ORACLE, 2022).
De acordo com a Oracle (2022), apenas armazenar os dados não é o suficiente. Eles devem ser usados para serem úteis, e isso depende de curadoria. Dados limpos ou relevantes para o cliente e organizados de maneira que permita uma análise significativa exigem muito trabalho. Ainda de acordo com a Oracle (2022), cientistas de dados gastam até 80 por cento de seu tempo fazendo a curadoria e preparação dos dados antes que estes possam ser utilizados.
Por fim, nota-se que a tecnologia de big data está mudando em ritmo acelerado. Há alguns anos, o Apache Hadoop era a tecnologia popular para esta finalidade. Em seguida, o Apache Spark foi introduzido em 2014. Hoje, uma combinação das duas estruturas parece ser a melhor abordagem. Manter-se atualizado com a tecnologia de big data é um desafio contínuo (ORACLE, 2022).
Tecnologias de Big Data
Os sistemas de Data Warehouse são tradicionalmente suportados por modelos multidimensionais predefinidos, tendo o intuito de prover suporte a aplicações de Business Intelligence. Tais modelos são geralmente implementados sobre bancos de dados relacionais e geridos por meio da linguagem SQL (Structured Query Language) (SALINAS e LEMUS, 2017). Embora SGBDs relacionais possam gerenciar grandes quantidades de informações, estes possuem certas limitações de escalabilidade horizontal, o que não ocorre com soluções de Big Data (MONGODB, 2022; SALINAS e LEMUS, 2017). A resposta às novas necessidades é a utilização de memória extensiva, distribuição de dados e paralelização de processamento, que de uma forma ou de outra estão incluídos no Apache Hadoop, Apache Spark, bases de dados NoSQL e tecnologias complementares a estas (SALINAS e LEMUS, 2017).
Apache Hadoop
O Apache Hadoop é um framework de código aberto usado para armazenar e processar com eficiência grandes conjuntos de dados que variam em tamanho de gigabytes a petabytes. Em vez de usar um grande computador para armazenar e processar os dados, o Hadoop permite agrupar (clustering) vários computadores para analisar conjuntos de dados massivos em paralelo (AMAZON, 2022). O Apache Hadoop é constituído por quatro módulos:
- Hadoop Distributed File System (HDFS): sistema de arquivos distribuído que é executado em hardware padrão ou de baixo custo. Oferece melhor taxa de transferência de dados do que os sistemas de arquivos tradicionais, além de alta tolerância a falhas e suporte nativo de grandes conjuntos de dados.
- Yet Another Resource Negotiator (YARN): Gerencia e monitora clusters de nós e utilização de recursos. Permite o agendamento de trabalhos e tarefas.
- MapReduce: framework que ajuda os programas a fazer a computação paralela em dados. A tarefa do map pega os dados de entrada e os converte em um conjunto de dados que pode ser calculado em pares de valores-chave. A saída do map é consumida pelas tarefas de reduce para agregar a saída e fornecer o resultado desejado.
- Hadoop Common: Fornece bibliotecas Java comuns que podem ser usadas em todos os módulos.
Apache Spark
O Apache Spark é um sistema de processamento distribuído de código aberto usado para processar cargas de trabalho de big data. Ele utiliza in-memory cache (cache em memória) e recursos de otimização de consultas para agilizar a execução de consultas analíticas em conjuntos de dados de qualquer tamanho. Ele fornece APIs de desenvolvimento em Java, Scala, Python e R e oferece suporte à reutilização de código em várias cargas de trabalho -- processamento em lote, consultas interativas, análise em tempo real, aprendizado de máquina e processamento de grafos. O Apache Spark é atualmente uma das estruturas de processamento distribuído de big data mais populares (AMAZON, 2022).
O Spark foi criado para resolver limitações do MapReduce, fazendo processamento em memória (in-memory), reduzindo o número de etapas de trabalho e reutilizando dados em várias operações paralelas. Com o Spark, apenas uma etapa é necessária onde os dados são lidos na memória, as operações são executadas e os resultados são gravados de volta, resultando em uma execução muito mais rápida.
O Spark também reutiliza dados usando um cache na memória para acelerar os algoritmos de aprendizado de máquina que chamam repetidamente uma função no mesmo conjunto de dados. A reutilização de dados é realizada por meio da criação de DataFrames, uma abstração sobre Resilient Distributed Dataset (RDD), que é uma coleção de objetos armazenados em cache na memória e reutilizados em várias operações do Spark. Isso reduz drasticamente a latência, tornando o Spark várias vezes mais rápido que o MapReduce, especialmente em trabalhos de aprendizado de máquina e análises interativas.
Apache Spark vs. Apache Hadoop
Fora as diferenças no design do Spark e do Hadoop MapReduce, muitas organizações consideram essas estruturas de big data complementares.
O Hadoop é um framework open source que possui o Hadoop Distributed File System (HDFS) como armazenamento, o YARN como forma de gerenciar os recursos computacionais utilizados por diferentes aplicações e uma implementação do modelo de programação MapReduce como mecanismo de execução.
Spark é um framework de código aberto, focado em consultas interativas, aprendizado de máquina e cargas de trabalho em tempo real. Ele não possui seu próprio sistema de armazenamento, mas executa análises em outros sistemas de armazenamento como HDFS ou outras soluções populares como Amazon Redshift, Amazon S3, Couchbase, Cassandra e outras. O Spark sendo executado sobre o Hadoop aproveita o YARN para compartilhar clusters conjuntos de dados comuns, bem como outros recursos do Hadoop, garantindo níveis consistentes de serviço e resposta.
Ecossistema Hadoop
O ecossistema Hadoop cresceu significativamente ao longo dos anos devido à sua extensibilidade. Hoje, o ecossistema Hadoop inclui muitas ferramentas e aplicativos para ajudar a coletar, armazenar, processar, analisar e gerenciar big data. Algumas das aplicações mais populares são (AMAZON, 2022):
Spark – Um sistema de processamento distribuído de código aberto comumente usado para cargas de trabalho de big data. O Apache Spark usa cache na memória e execução otimizada para desempenho rápido e oferece suporte a processamento geral em lote, análise de streaming, aprendizado de máquina, bancos de dados de grafos e consultas ad-hoc.
Presto - Um mecanismo de consulta SQL distribuído de código aberto otimizado para análise de dados ad-hoc de baixa latência. Ele suporta o padrão ANSI SQL, incluindo consultas complexas, agregações, junções e funções de janela. O Presto pode processar dados de várias fontes de dados, incluindo o Hadoop Distributed File System (HDFS) e o Amazon S3.
Hive - Permite que os usuários aproveitem o Hadoop MapReduce usando uma interface SQL, permitindo análises em grande escala, além de armazenamento de dados distribuído e tolerante a falhas.
HBase - Um banco de dados com versão não relacional e de código aberto executado no Amazon S3 (usando EMRFS) ou no Hadoop Distributed File System (HDFS). O HBase é um armazenamento de big data distribuído e massivamente escalável, criado para acesso aleatório, estritamente consistente e em tempo real para tabelas com bilhões de linhas e milhões de colunas.
Bancos de Dados NoSQL
O termo NoSQL refere-se a um conjunto de sistemas de gerenciamento de bancos de dados baseados em estruturas não relacionais e sem um esquema pré-definido, que facilitam a escalabilidade horizontal e a gestão de dados não estruturados. Para melhorar o desempenho desses bancos de dados, as propriedades transacionais de conformidade ACID (Atomicity, Consistency, Isolation, Durability) não são garantidas, aderindo ao princípio de design BASE (basic availability, soft state, eventually consistent). O teorema CAP afirma que um sistema distribuído só pode fornecer simultaneamente duas propriedades entre consistência (C), disponibilidade (A) e tolerância à partição (P). A conformidade com ACID mantém consistência e disponibilidade, abrindo mão da possibilidade de implementações distribuídas em paralelo. O BASE, em vez disso, adota a tolerância à partição e, portanto, abre mão da disponibilidade imediata (CP) ou da consistência imediata (AP), dependendo do tipo de requisitos na camada de aplicação (SALINAS e LEMUS, 2017).
Bancos de dados NoSQL podem ser agrupados em bancos de dados documentais, de colunas (column-family), de valores-chave (key-value) ou grafos. Em bancos de dados orientados a documentos, cada registro é armazenado como um documento que é encapsulado e codificado em um formato padrão semi-estruturado como XML, JSON, BSON, etc.. Os bancos de dados orientados a documentos mais populares são MongoDB e CouchDB. Os bancos de dados orientados a colunas são caracterizados pela agregação de colunas de dados dentro de contêineres dados (keyspace). Algumas implementações deste tipo são Google BigTable, Cassandra, Apache HBase, Hypertable e Cloudata. Os bancos de dados orientados a valores-chave são caracterizados por armazenar dados como pares de valores-chave. Isso funciona eficientemente na memória usando estruturas map, arrays associativos ou tabelas hash, e também gerencia o armazenamento persistente. Apache Accumulo, CouchDB, Amazon Dynamo e Redis, entre outros, são os bancos de dados de chave-valor mais usados. Por fim, os bancos de dados orientados a grafos são caracterizados por uma organização de armazenamento diferente, na qual cada nó representa um objeto que pode estar relacionado a outros objetos por meio de uma ou mais arestas direcionadas (que, também, podem ser objetos). Dentro desta categoria podemos citar Neo4J, AllegroGraph e FlockDB. Em certos casos, bancos de dados orientados a grafos podem ser configurados para cumprir as propriedades ACID (SALINAS e LEMUS, 2017).
Salinas e Lemus (2017) mencionam sobre a utilização de bancos de dados NoSQL para a construção de Data Warehouses. Considerando a utilização da Modelagem Dimensional na estruturação de Data Warehouses, aparentemente a utilização de bancos de dados NoSQL não aparenta ser a melhor opção, como demonstrado por Pereira, Oliveira e Rodrigues (2015). Em seu trabalho, estes autores comparam o desempenho de um DW construído sobre o SQL Server (banco de dados relacional) e o MongoDB (banco de dados NoSQL).
Big Data vs Data Warehouse
Diferentemente de um Data Warehouse, o Big Data vai além da consolidação de informações, pois é utilizado principalmente para o armazenamento e processamento de qualquer tipo e volume de dados com um volume que potencialmente cresce exponencialmente. De certo modo, Data Warehouse (DW) e Big Data (BD) possuem o mesmo propósito, isto é, prover suporte a tomada de decisões, explorar dados para a identificação de padrões, geração de estatísticas e indicadores de desempenho (SALINAS e LEMUS, 2017).
As diferenças entre DW e BD estão na natureza dos dados, nos usuários a que são destinados e nos procedimentos e ferramentas para aquisição, armazenamento e análise de dados. Big Data foca principalmente na exploração de dados brutos, como dados não estruturados e não repetíveis, não susceptíveis a agregações e tratamentos sistemáticos. Por isso, geralmente, usuários de Big Data são mais especializados (por exemplo, cientistas de dados), que com a utilização de ferramentas, técnicas e algoritmos especiais conseguem identificar padrões que resultam em conclusões valiosas. Data Warehouses são focados em dados estruturados e alguns tipos de dados não estruturados, que precisam ser pré-processados antes de serem disponibilizados aos usuários finais (que podem não ter o conhecimento necessário de mineração de dados ou outras conhecimentos específicos), deste modo, estes podem fazer análises independentemente da origem dos dados, tipo de armazenamento, arquitetura, ferramentas e algoritmos específicos (SALINAS e LEMUS, 2017).
Para Salinas e Lemus (2017), a integração de conjuntos de dados heterogêneos pode ser a principal diferença entre um Data Warehouse e uma aplicação de Big Data. Em um DW, o propósito de uma integração é a obtenção de uma visão uniforme da organização, enquanto que em uma aplicação de BD, a integração não consiste em seu objetivo final. Neste último caso, conjuntos de dados não estruturados não passíveis de integração devem ser mantidos em seu formato original, permitindo a possibilidade de usos futuros, não previsíveis para o momento.
Em seu artigo, Salinas e Lemus (2017) concluem que aplicações de Big Data não constituem uma evolução para Data Warehouses. Na realidade DW e BD são complementares e podem ser integrados para o compartilhamento não apenas de dados, mas também de armazenamento e demais recursos computacionais.
Salinas e Lemus (2017) alertam que a demanda por soluções rápidas e a versatilidade de algumas ferramentas têm levado ao desenvolvimento de projetos de DW sem a utilização de metodologias e frameworks adequados. Após o investimento de tempo e recursos financeiros, organizações têm se visto presas em “soluções” de DW/BI que não cumprem as expectativas iniciais, inflexíveis a mudanças, difíceis de manter e escalar. Em relação a soluções de Big Data, existe atualmente todo um ecossistema de tecnologias, não necessariamente integradas em uma única plataforma, que pode aumentar a complexidade de desenvolvimento de novos projetos.
Big Data substitui a necessidade de um Data Warehouse?
Como já mencionado por Salinas e Lemus (2017), Big Data e Data Warehouse são complementares. Esta é também uma visão da Oracle (2022), ao afirmar que muitos veem big data como uma extensão integral de seus recursos existentes de business intelligence, plataforma de data warehousing e arquitetura de informações.
Para Anand (2019), uma solução de Big Data é uma tecnologia, enquanto que Data Warehousing seria um conceito arquitetônico em computação de dados. Uma organização pode ter diferentes combinações, com apenas soluções de Big Data ou de Data Warehouse, ou ambas simultaneamente, a depender dos seguintes fatores: Estrutura dos dados na origem; volume de dados; velocidade com que os dados deverão estar disponíveis para análise; e nível de conhecimento dos usuários dos dados.
Do ponto de vista do usuário final, em um DW, os dados armazenados estão sempre prontos para serem consumidos, mas são limitados aos dados já armazenados. Os dados em um DW estarão orientados por assunto/processo de negócio, portanto mais facilmente entendíveis por usuários finais. No entanto, se os usuários precisam de dados não presentes em um DW (como por exemplo, dados de redes sociais ou de algum log), a inclusão poderá não ser ágil devido ao processo necessário para coleta, tratamento e ingestão de dados de forma estruturada e organizada. Tais dados poderiam ser direcionados a uma solução de Big Data, permitindo com que os usuários pudessem acessá-los em formato nativo, mas que precisariam de transformações para a elaboração de relatórios. A recuperação de dados presentes em soluções de Big Data é difícil, pois os dados armazenados são desestruturados e desorganizados (ANAND, 2019).
Análise de big data (Big data analytics)
De acordo com o SAS (2022), técnicas de big data analytics (análise de big data) examinam grandes quantidades de dados na tentativa de descobrir padrões ocultos, correlações e outros insights.
Para Gandomi e Haider (2015), o potencial do big data surge apenas quando aproveitado para apoiar na tomada de decisões. Para isso, são necessários processos eficientes para transformar grandes volumes de dados, diversos e rápidos, em insights significativos.
O processo geral de extração de insights de big data pode ser dividido em cinco etapas, como pode ser visto na Figura 1.
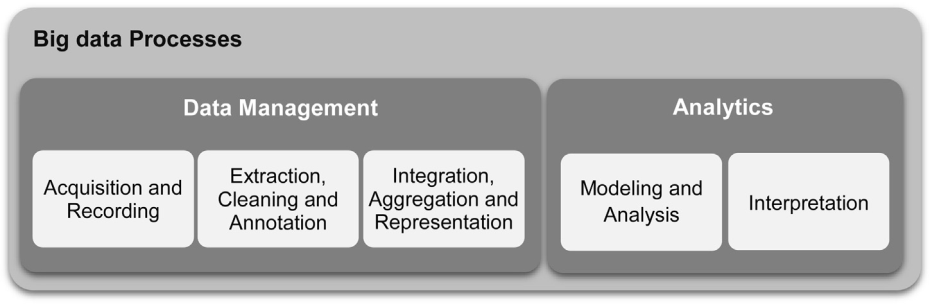
Figura 1: Proceso geral de big data. Fonte: GANDOMI e HAIDER (2015).
Esses cinco estágios formam os dois principais subprocessos: gerenciamento de dados (Data Management) e análise (Analytics). O gerenciamento de dados envolve processos e tecnologias para adquirir, armazenar e preparar os dados para análise. A análise (Analytics), por outro lado, refere-se às técnicas usadas para analisar e adquirir inteligência a partir de big data. Deste modo, a análise de big data (Big data analytics) pode ser vista como um subprocesso no processo geral de “extração de insights” de big data (GANDOMI e HAIDER, 2015).
De acordo com o SAS (2022), não há uma tecnologia única que englobe a análise de big data. Existem análises avançadas que podem ser aplicadas a big data, mas, na realidade, vários tipos de tecnologia e técnicas precisam trabalhar juntas para a máxima obtenção de valor sobre os dados. SAS (2022) menciona os seguintes componentes relacionados à análise de big data:
- Aprendizado de máquina: subconjunto específico de Inteligência Artificial, que possibilita a produção de modelos que podem analisar dados maiores e mais complexos e fornecer resultados mais rápidos e precisos – mesmo em uma escala muito grande. Ao construir modelos precisos, uma organização terá mais chances de identificar oportunidades lucrativas – ou evitar riscos desconhecidos;
- Gestão de dados: os dados precisam ser de alta qualidade e bem governados antes que possam ser analisados de forma confiável. Com os dados entrando e saindo constantemente de uma organização, é importante estabelecer processos repetíveis para criar e manter padrões de qualidade de dados. Uma vez que os dados sejam confiáveis, as organizações devem estabelecer um programa de gerenciamento de dados mestres que coloque toda a empresa na mesma página;
- Mineração de dados: tecnologias de mineração de dados ajudam a examinar grandes quantidades de dados para descobrir padrões – e essas informações podem ser usadas para análises adicionais para ajudar a responder a questões comerciais complexas. Com o software de mineração de dados, pode-se filtrar todo o ruído caótico e repetitivo nos dados, identificar o que é relevante, e usar essas informações para avaliar resultados prováveis e acelerar o ritmo de tomada de decisões;
- Hadoop: este framework de código aberto pode armazenar grandes quantidades de dados e executar aplicativos em clusters de hardware comuns. Tornou-se uma tecnologia chave em big data;
- Análise in-memory: Ao analisar os dados da memória do sistema (em vez da unidade de disco rígido), você pode obter insights imediatos de seus dados e agir rapidamente. Essa tecnologia é capaz de remover latências de preparação de dados e processamento analítico para testar novos cenários e criar modelos; não é apenas uma maneira fácil para as organizações permanecerem ágeis e tomarem melhores decisões de negócios, mas também permite que elas executem cenários de análise iterativos e interativos;
- Análise preditiva: a tecnologia de análise preditiva usa dados, algoritmos estatísticos e técnicas de aprendizado de máquina para identificar a probabilidade de resultados futuros com base em dados históricos. Trata-se de fornecer uma melhor avaliação sobre o que acontecerá no futuro, para que as organizações possam se sentir mais confiantes de que estão tomando a melhor decisão de negócios possível;
- Mineração de texto: com a tecnologia de mineração de texto, pode-se analisar dados de texto da web, campos de comentários, livros e outras fontes baseadas em texto para descobrir insights, antes não notados. A mineração de texto usa aprendizado de máquina ou tecnologia de processamento de linguagem natural para vasculhar documentos – e-mails, blogs, feeds do Twitter, pesquisas, inteligência competitiva e muito mais – para auxiliar na análise de grandes quantidades de informações e descobrir novos tópicos e relacionamentos de termos.
Gandomi e Haider (2015) descrevem as cinco técnicas de análise de big data mais relevantes, de acordo com os autores. As técnicas descritas são listadas abaixo. Para mais detalhes, consultar o artigo referenciado:
- Análise de texto: também chamado de mineração de texto, esta técnica refere-se à extração de informações a partir de dados textuais, como feeds de notícias, e-mails, blogs, fóruns, notícias, questionários, logs de call center, etc;
- Análise de áudio: extração de informações de dados de áudio não estruturados. Quando aplicado à análise da linguagem falada, é também chamado de análise de fala;
- Análise de vídeo: também conhecido como video content analysis (VCA), ou análise de conteúdo de vídeo, envolve uma variedade de técnicas para monitorar, analisar e extrair informações a partir de streams de vídeo;
- Análise de mídias sociais: análise de dados estruturados e não estruturados provenientes de canais de mídias sociais (facebook, linkedin, twitter, instagram, tumblr, etc.);
- Análises preditivas: análise preditiva compreende uma variedade de técnicas que preveem resultados futuros com base em dados históricos e atuais. Na prática, a análise preditiva pode ser aplicada a quase todas as disciplinas – desde prever a falha de motores a jato com base no fluxo de dados de vários milhares de sensores, até prever os próximos movimentos dos clientes com base no que compram, quando compram e até mesmo no que dizem nas redes sociais. Em sua essência, a análise preditiva busca descobrir padrões e capturar relacionamentos nos dados.
Data Lake
Embora Data Warehouses sejam ainda muito relevantes e muito poderosos para dados estruturados, não se pode dizer o mesmo para dados semi-estruturados e não estruturados (KHINE e WANG, 2018; SAWADOGO e DARMONT, 2021). Como a maioria dos dados provenientes de Big Data são dados não estruturados (MILOSLAVSKAYA e TOLSTOY, 2016), pode-se concluir que Data Warehouses tradicionais não mostram-se alternativas viáveis como fonte de dados analíticos de Big Data. Neste sentido, o conceito de Data Lake desafia os tradicionais Data Warehouses no armazenamento de dados heterogêneos e complexos (KHINE e WANG, 2018).
As definições para Data Lake têm variado ao longo do tempo (KHINE e WANG, 2018; SAWADOGO e DARMONT, 2021). Alguns autores definem Data Lake apenas como um novo rótulo para soluções como Apache Hadoop por exemplo, o que, segundo Sawadogo e Darmont (2021) não estaria correto. Outros autores afirmam que Data Lakes podem ser utilizados apenas por alguns profissionais específicos, como estatísticos e cientistas de dados, pois os dados armazenados neste tipo de repositório requer certos cuidados que usuários de negócio poderiam negligenciar. Para Sawadogo e Darmont (2021), a definição mais correta para Data Lake é:
“um sistema escalável de armazenamento e análise de dados de qualquer tipo, retido em seu formato nativo e utilizado principalmente por especialistas em dados (estatísticos, cientistas de dados ou analistas) para extração de conhecimento. Suas características incluem:
- um catálogo de dados que reforça a qualidade dos dados;
- ferramentas e políticas de governança de dados;
- acessível por vários tipos de usuários;
- integração de qualquer tipo de dado;
- organização física e lógica;
- escalabilidade em termos de armazenamento e processamento.“.
Para Sawadogo e Darmont (2021), Data Lakes não necessariamente precisam ser restritos a estatísticos e cientistas de dados. Na visão destes autores, especialistas de negócio podem acessar Data Lakes através de um software de navegação ou de análise de dados apropriados.
De acordo com a Amazon (2022), um Data Lake é um repositório centralizado que permite armazenar dados estruturados e não estruturados, em qualquer escala. Os dados podem ser armazenados como estão, sem precisar primeiro estruturá-los. Uma vez armazenados, podem ser executadas diferentes tipos de análises sobre os dados, desde painéis e visualizações até processamento de big data, análise em tempo real e aprendizado de máquina.
Para Khine e Wang (2018), Data Lake consiste em um repositório em que todos os dados de uma organização, ou seja, dados estruturados, semi estruturados e não estruturados, são armazenados juntos, independentemente dos tipos, formato ou estrutura. Em um Data Lake, o entendimento dos dados, da sua estrutura e natureza, é delegada ao consumidor do dado, no momento da recuperação (ou seja, no momento da consulta). Os dados são transformados pelo usuário, ou aplicação, de acordo com o setor da organização, no intuito de adquirir insights de negócios. Alguns Data Lakes possuem recursos que possibilitam a criação de uma camada semântica sobre os dados, que permitem a construção de uma camada de contexto, significado e relacionamento entre os dados armazenados. (KHINE e WANG, 2018).
No contexto de um Data Lake, todos os dados são primeiramente coletados de suas fontes (Extract - E), depois carregados no Data Lake (Load - L), sem modificação de seus formatos originais, e por fim são transformados (Transform - T), de acordo com o interesse do cliente consumidor (KHINE e WANG, 2018). Ou seja, com Data Lake temos o acrônimo ELT, ao invés do ETL utilizado no Data Warehouse.
Sawadogo e Darmont (2021) apresentam diversas arquiteturas de Data Lakes, e concluem que tanto as arquiteturas funcionais quanto as arquiteturas baseadas em maturidade de dados são limitadas, e expõem a necessidade de uma arquitetura que aborde simultaneamente, funcionalidade e maturidade de dados.
A maioria dos Data Lakes são construídos sobre o ecossistema Apache Hadoop (HDFS, MapReduce, Spark, etc.), mas como exposto por Sawadogo e Darmont (2021), esta não é a única alternativa, visto que a construção de um Data Lake exige diversas partes básicas, tais como:
- Ingestão de dados: esta etapa envolve a transferência de dados para o Data Lake. Alguns exemplos de ferramentas utilizadas são: Flink, Samza, Flume, Kafka e Sqoop.
- Armazenamento: de acordo com Sawadogo e Darmont (2021), existem duas abordagens para armazenamento de dados em Data Lakes. A primeira é por meio da utilização de SGBDs tradicionais, como MySQL, PostgreSQL e Oracle. Geralmente, estes SGBDs são utilizados para armazenamento de dados estruturados e possuem também alguns recursos para armazenamento de dados não estruturados. Mas, geralmente, bancos de dados NoSQL são utilizados para o armazenamento de dados estruturados e não estruturados. A segunda forma é por meio do HDFS, utilizado em torno de 75% das vezes para armazenamento de dados em Data Lakes. No entanto, de acordo com Sawadogo e Darmont (2021), o HDFS sozinho é geralmente insuficiente para lidar com todos os formatos de dados, especialmente dados estruturados. Deste modo, segundo os autores, o ideal é que seja feita uma combinação do HDFS com bancos de dados relacionais e/ou NoSQL.
- Processamento de dados: em Data Lakes, o processamento de dados é geralmente feito com o MapReduce ou Apache Spark. O Spark funciona como o MapReduce, mas adota uma abordagem de processamento 100% em memória ao invés de utilizar armazenamento físico para resultados parciais. Deste modo, spark é preferível para processamento de dados em tempo real. O Apache Flink e o Apache Storm são também boas alternativas para o processamento de dados em tempo real. As duas abordagens podem ser utilizadas simultaneamente, com o MapReduce dedicado ao processamento de grandes volumes de dados, e outros motores para o processamento de dados em tempo real.
- Acesso aos dados: Em Data Lakes, o acesso a dados pode ser feito por SQL para bancos de dados relacionais, JSONiq para MongoDB, XQuery para bancos de dados XML ou SPARQL para recursos RDF. No entanto, isto não permite a execução de consultas sobre bancos de dados heterogêneos, visto que, geralmente, Data Lakes são construídos sobre uma arquitetura heterogênea (SAWADOGO e DARMONT, 2021). Deste modo, uma alternativa consiste na adoção de soluções capazes de realizar consultas em múltiplas fontes simultaneamente. Por exemplo, Spark SQL, ou SQL++ podem ser utilizados para a recuperação tanto de dados em SGBDs relacionais quanto dados semi estruturados no formato JSON. Outro exemplo é o Apache Drill, que permite consultas e junções sobre dados provenientes de múltiplas fontes. Usuários de negócio têm utilizado ferramentas de visualização amigáveis para visualizar dados em Data Lakes, como o Microsoft Power BI e o Tableau.
Combinando Data Lakes com Data Warehouses
Sawadogo e Darmont (2021) citam duas abordagens de combinação de Data Lakes com Data Warehouses. A primeira utiliza o Data Lake como fonte de dados para o DW, para onde os dados susceptíveis ao rigor do processo de ETL são enviados, enquanto os dados remanescentes ficam disponíveis para análises complementares. A segunda abordagem considera a construção de um DW dentro do Data Lake. Algo que, segundo Sawadogo e Darmont (2021), seria possível com a abordagem de subdivisão do Data Lake em data ponds, proposta por Inmon (2016). Data ponds estruturados a partir de aplicações operacionais poderiam ser considerados equivalentes a Data Warehouses (INMON, 2016).
Oreščanin e Hlupić (2021) mencionam uma combinação entre Data Wharesouse e Data Lake que envolve a migração de dados históricos de um DW para um Data Lake. De acordo com os autores, nesta configuração, o DW teria a função de armazenar os dados (fatos) mais recentes, e, à medida em que o DW for aumentando de tamanho, os dados mais antigos, e portanto menos acessados, poderiam ser migrados para a Foundation Area de um Data Lake. Deste moto, o DW ganharia performance de consulta e espaço em disco. Nesta configuração, os dados armazenados no Data Lake continuariam acessíveis e prontos para serem analisados juntamente com os dados no DW.
Maturidade e segurança
Caso o Data Lake não seja gerenciado adequadamente, este pode deteriorar-se a tal ponto de tornar-se o que é chamado de data swamp (pantano de dados) (KHINE e WANG, 2018; OREŠČANIN e HLUPIĆ, 2021). Ninguém sabe exatamente o que será incluído em um Data Lake, não havendo procedimentos para prevenção de inclusão de dados inconsistentes ou repetidos, por exemplo. Se ninguém sabe exatamente o que há no Data Lake até a extração, dados corrompidos podem ser utilizados equivocadamente em tomadas de decisão, fazendo com que o erro seja descoberto tarde demais (KHINE e WANG, 2018). De acordo com Sawadogo e Darmont (2021), a gestão de metadados é fundamental para impedir que o Data Lake se torne um data swamp.
Neste mesmo sentido, Khine e Wang (2018) afirmam que a gestão de metadados é fundamental em um Data Lake. Como a forma de armazenamento não possui schemas pré-definidos (schema-on-ready), como em um Data Warehouse (que é schema-on-write), o Data Lake precisa fornecer metadados aos clientes durante o processo de análise e realização de consultas. Os metadados precisam ser adicionados no momento de armazenamento dos dados. Deste modo, a definição de uma arquitetura coerente, juntamente com a gestão de metadados, são cruciais para a qualidade de dados.
Begoli, Goethert e Knight (2021) afirmam que Data Lakes não impõem explicitamente um schema para armazenamento de dados. Este aspecto, em um cenário de crescimento exponencial de dados, provenientes de inúmeras fontes, pode transformar o Data Lake em um Data Swamp, ou seja, em um pântano cheio de detritos de dados.
De acordo com Sawadogo e Darmont (2021), temas como governança de dados e segurança em Data Lakes são atualmente pouco abordados pela literatura. De acordo com Khine e Wang (2018), Data Warehouses podem garantir governança, performance, segurança e controle de acesso aos dados, enquanto Data Lakes não podem garantir, de forma plena, nenhum destes aspectos. Neste sentido, Khine e Wang (2018) afirmam que gerar valor com Data Lakes é ainda algo muito difícil.
Data Lakehouse
Data Lakes, como um conceito moderno de armazenamento de dados em formato nativo, foi apresentado como um substituto para Data Warehouses. No entanto, com o passar do tempo, ficou claro que Data Lakes pode ser utilizado em complementação ao Data Warehouses, não como substituto (OREŠČANIN e HLUPIĆ, 2021).
Data Warehouses (DW) surgiram com o intuito de auxiliar usuários de negócio a obterem insights analíticos através da centralização de dados provenientes de diversas fontes, principalmente de bancos de dados operacionais. Os dados em um DW são utilizados como suporte à tomada de decisão por meio de aplicações de Business Intelligence (BI). Os dados em um DW são armazenados em uma estrutura fixa, em schemas pré-definidos (schema-on-write), de modo a garantir segurança e performance. Este tipo de solução é chamado de plataforma de análise de dados de primeira geração (ARMBRUST, GHODSI, XIN e ZAHARIA, 2021).
Com o surgimento do Big Data (grande volume de dados, em grande velocidade e variedade de fontes e múltiplos formatos), os Data Warehouses passaram a não conseguir suprir as necessidades de algumas organizações, surgindo então a segunda geração de plataforma de análise de dados, os Data Lakes (ARMBRUST, GHODSI, XIN e ZAHARIA, 2021). Data Lakes utilizam formas de armazenamento de baixo custo (HDFS do Apache Hadoop, por exemplo) e, geralmente, com formatos de armazenamento abertos, como Apache Parquet e ORC. Data Lakes possuem arquitetura schema-on-read, ou seja, os dados não são armazenados em estruturas rígidas pré-definidas, e sim em seu formato original. Fornecendo flexibilidade e agilidade no armazenamento e acesso aos dados. Porém, por outro lado, a flexibilidade trazida por Data Lakes traz problemas de qualidade e governança de dados, como já apontado por Khine e Wang (2018) e Sawadogo e Darmont (2021).
De 2015 em diante surgiu uma nova forma de organização das plataformas de dados, com a utilização complementar de Data Lakes e Data Warehouses. Data Lakes em nuvem, como S3, ADLS e GCS têm substituído o Apache HDFS, com o armazenamento posterior de parcela dos dados em Data Warehouses, como Redshift e Snowflake (ARMBRUST, GHODSI, XIN e ZAHARIA, 2021). Esta arquitetura de duas camadas, Data Lake + Data Warehouse é, segundo Armbrust, Ghodsi, Xin e Zaharia (2021), dominante no mercado (aparentemente utilizado por todas as empresas do ranking Fortune 500).
Esta arquitetura de duas camadas possui alta complexidade de manutenção. Primeiramente os dados são carregados em um Data Lake, e depois em um Data Warehouse, exigindo portanto duas etapas de ETL até a sua disponibilização para análise por usuários de BI. A nova arquitetura, portanto, aumentou a complexidade, os atrasos e os pontos de falha se comparada à estratégia de inclusão de dados diretamente no Data Warehouse, por exemplo (ARMBRUST, GHODSI, XIN e ZAHARIA, 2021).
Diante dos problemas ainda não solucionados por Data Warehouses e/ou Data Lakes, surge um novo conceito de arquitetura denominado Data Lakehouse, com o objetivo de superar tais problemas (OREŠČANIN e HLUPIĆ, 2021).
Um Data Lakehouse busca combinar as vantagens das arquiteturas presentes em Data Lakes e Data Warehouses, contendo tanto estruturas de dados pré-definidas (schema-on-write), quanto não pré-definidas (schema-on-read) (OREŠČANIN e HLUPIĆ, 2021).
Conceitualmente, um Data Lakehouse promete conciliar as demandas de armazenamento de dados heterogêneos de modo eficiente e econômico, permitindo o acesso aos mesmos por meio de diversos tipos de aplicações, desde aquelas baseadas em aprendizado de máquina àquelas baseadas em SQL. De modo geral, Data Lakehouses buscam solucionar os problemas de confiabilidade e obsolescência de dados, suporte limitado a análises avançadas e diminuição do custo total de propriedade das arquiteturas de dados (BEGOLI, GOETHERT E KNIGHT, 2021).
Definição
Armbrust, Ghodsi, Xin e Zaharia (2021) definem um Data Lakehouse como um sistema de gerenciamento de dados baseado em armazenamento de baixo custo e de acesso direto, que também fornece recursos de desempenho e gerenciamento analíticos tradicionais de SGBDs, como transações ACID, controle de versão de dados, auditoria, indexação, armazenamento em cache e otimização de consultas. Deste modo, Lakehouses combinam os principais benefícios de Data Lakes e Data Warehouses: armazenamento de baixo custo em formatos abertos e acessíveis, e poderosos recursos de gerenciamento e otimização. A questão-chave é se é possível combinar esses benefícios de maneira eficaz: em particular, o suporte de Lakehouses para acesso direto aos dados significa que eles abrem mão de alguns aspectos de independência de dados, que tem sido um dos pilares do design de SGBDs relacionais.
Begoli, Goethert e Knight (2021) afirmam que o conceito de Data Lakehouse ainda é vago, não materializado. De acordo com os autores, não há ainda uma solução completa definitiva, “fora da prateleira”, para o conceito de Data Lakehouse. Ou seja, é ainda um conceito em evolução, que parte das seguintes premissas:
- Data Lakes oferecem suporte a uma gestão de dados eficiente;
- Formatos abertos (Apache Parquet, OCR, etc.) provêem suporte a ferramentas e bibliotecas de inteligência artificial / aprendizado de máquina;
- O estado da arte em performance SQL pode ser reproduzido sobre formatos abertos.
Direcionamento da indústria
Armbrust, Ghodsi, Xin e Zaharia (2021) argumentam que a arquitetura de Data Warehouse como a conhecemos hoje tende a perder importância nos próximos anos, e deverá ser substituída por um novo padrão arquitetônico, o Data Lakehouse que:
- Será baseado em formatos de dados abertos de acesso direto, como Apache Parquet;
- Terá suporte de primeira classe para aprendizado de máquina e ciência de dados;
- Oferecerá desempenho de última geração.
De acordo com Armbrust, Ghodsi, Xin e Zaharia (2021), Data Lakehouses podem ajudar a enfrentar vários desafios importantes enfrentados atualmente com Data Lakes e Data Warehouses, incluindo:
- Dados desatualizados;
- Confiabilidade;
- Custo total de propriedade;
- Aprisionamento de dados;
- Suporte limitado a casos de uso específicos.
Armbrust, Ghodsi, Xin e Zaharia (2021) concluem que a indústria tende a convergir para a adoção de Data Lakehouses devido à vasta quantidade de dados já depositados atualmente em Data Lakes, e devido à grande oportunidade de simplificação das suas arquiteturas de dados.
Figrua 1: Evolução das arquiteturas de plataforma de dados. Fonte: (ARMBRUST, GHODSI, XIN e ZAHARIA, 2021).
Data Mesh
Em 2019, no artigo How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh, Zhamak Dehghani propõe uma nova abordagem para construção de plataformas de dados, chamado Data Mesh. De acordo com Dehghani (2019), os modelos atuais de plataforma de dados, sendo estes baseados em Data Lakes ou Data Warehouses, são centralizados, monolíticos e agnósticos a domínios (áreas de negócio). Embora inúmeras organizações tenham investido fortemente na construção de soluções que facilitem a tomada de decisão orientada por dados, como plataformas de dados e inteligência, estas organizações têm considerado os resultados medíocres (DEHGHANI, 2019).
Dehghani (2019) reconhece a necessidade de usuários de dados, como cientistas de dados e analistas, terem acesso simplificado a um conjunto diversificado de dados, bem como a necessidade de separar o uso de dados de sistemas operacionais dos dados consumidos para fins analíticos. Mas propõe que os modelos de solução centralizados existentes não são a resposta ideal para grandes empresas com múltiplos domínios (áreas de negócio), onde novas fontes de dados são continuamente adicionadas.
Dehghani (2019) complementa que não defende a fragmentação em silos de conjunto de dados orientados a domínios (áreas de negócio), ocultos sob algum sistema de informação e geralmente difíceis de descobrir, entender e consumir. Tão pouco a existência de vários Data Warehouses (ou Data Lakes) fragmentados em decorrência de anos de dívidas técnicas acumuladas. Dehghani (2019) argumenta que a resposta a esses silos acidentais de dados inacessíveis não é criar uma plataforma de dados centralizada, com uma equipe centralizada que possui e faz a curadoria dos dados de todos os domínios (áreas de negócio), pois este tipo de solução não é escalável.
Dehghani (2019) define as gerações de plataformas de dados da seguinte forma:
- Primeira geração: Data Warehouses proprietários e plataformas de Business Intelligence e alto custo, que deixaram as organizações com um elevado débito técnico (diversos processos de ETL insustentáveis, tabelas e relatórios que apenas um pequeno grupo de profissionais especializados conseguiam entender).
- Segunda geração: Um ecossistema de big data com Data Lake como solução para todos os problemas. Soluções complexas de big data e jobs em lote de longa duração, geridos por uma equipe central de engenheiros de dados super especializados que criam Data Lakes monstruosos, que, na melhor das hipóteses, permitem algumas poucas análises de P&D (Pesquisa e Desenvolvimento); com mais promessas que realizações.
- Terceira geração: Geração atual de plataforma de dados, similar à geração anterior, porém com um toque moderno de:
- streaming para disponibilização de dados em tempo real com arquiteturas como o Kappa;
- unificação de processos em lote com streaming de processamento de dados através de frameworks como o Apache Beam;
- utilização extensa de serviços de gerenciamento em nuvem para armazenamento de dados, motores de execução de pipelines de dados e plataformas de aprendizado de máquina.
Embora a última geração de plataforma de dados tenha abordado algumas lacunas das gerações anteriores, como a análise de dados em tempo real e redução do custo de gerenciamento da infraestrutura de big data, esta ainda sofre de muitas das características subjacentes que levaram aos fracassos das gerações anteriores (DEHGHANI, 2019).
Falhas das arquiteturas atuais
De acordo com Dehghani (2019), as arquiteturas atuais possuem os seguintes problemas:
- Centralizada e monolítica:
- De modo geral, uma arquitetura de dados possui os os objetivos de: (a) coletar dados de inúmeras fontes; (b) limpar, enriquecer e transformar os dados coletados; e (c) servir conjuntos de dados para inúmeros consumidores, com diversas necessidades.
- As arquiteturas de dados atuais armazenam dados que logicamente pertencem a diversos domínios, como por exemplo: “alunos”, "servidores", “almoxarifado”, “compras”, etc.
- Enquanto na última década tenhamos aplicado de forma bem sucedida o conceito de design orientado a domínios em nossas aplicações (com a utilização de microsserviços), desconsideramos amplamente os conceitos de domínio em uma plataforma de dados. Criamos o maior monolítico de todos, a plataforma de big data. Enquanto esta abordagem possa funcionar para organizações com poucos domínios e pouca diversidade de casos de uso para os dados, o mesmo não acontece para organizações com inúmeros domínios, inúmeras fontes de dados e grande diversidade de consumidores de dados.
- Existem dois pontos críticos em uma arquitetura de dados centralizada:
- Dados ubíquos e proliferação de fontes: à medida que mais dados tornam-se onipresentes, a capacidade de consumir tudo e harmonizá-los em um só lugar diminui. A velocidade de resposta à proliferação de novas fontes de dados tende a diminuir, uma vez que precisaremos incluí-las todas em uma mesma plataforma centralizada.
- Agenda contínua de inovações e proliferação de consumidores de dados: cada vez mais, as organizações precisam disponibilizar uma grande quantidade de casos de uso de consumo de dados em suas plataformas, o que leva a uma crescente necessidade de novas transformações, agregações e projeções de dados para satisfazer o ciclo de teste e aprendizado envolvido no processo de inovação. O longo tempo de resposta para satisfazer as necessidades de consumidores de dados tem sido historicamente um ponto de atrito organizacional, e continua sendo nas arquiteturas modernas de plataformas de dados.
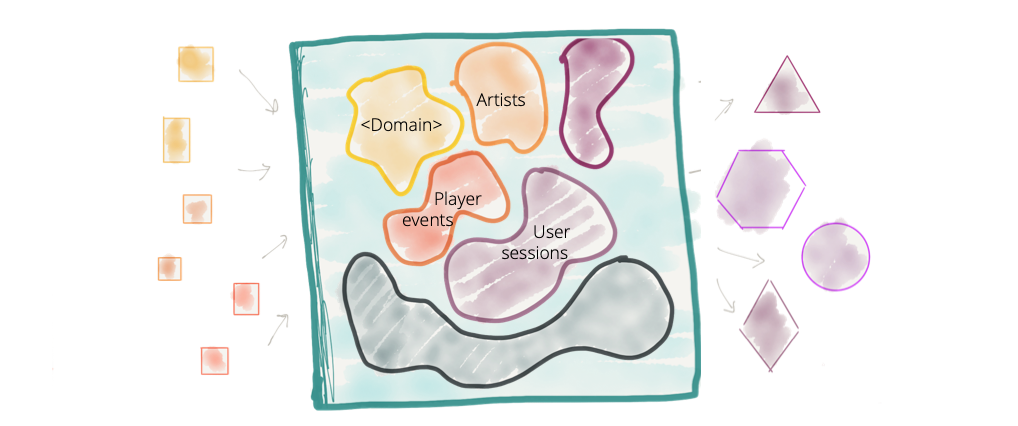
Figura 1: Plataforma de dados centralizada sem a clara definição de fronteiras entre dados de domínios distintos. Fonte: (DEHGHANI, 2019).
- Pipelines acoplados
-
- Como já mencionado, a inclusão ou alteração de fontes de dados, bem como a mudança de requisitos dos clientes faz com que a plataforma de dados aumente de tamanho.
- O modelo atual, que de forma resumida podemos sumarizar como: inclusão, processamento e disponibilização de dados, possui estágios fortemente acoplados. E embora seja possível um certo nível de escalabilidade, através da alocação de equipes à entregas específicas, este acoplamento excessivo entre os estágios limita a independência de entregas de novos valores e funcionalidades. Este acoplamento excessivo limita a velocidade de resposta a novos requisitos e/ou inclusão de novas fontes de dados.
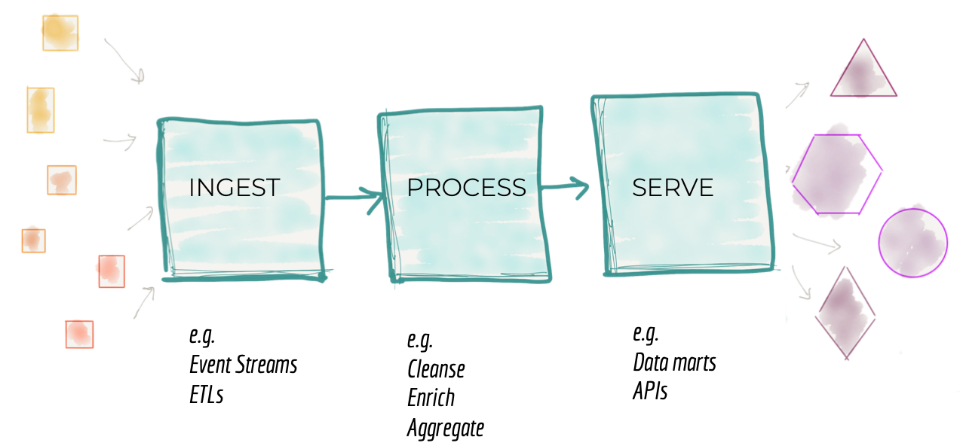
Figura 2: Decomposição arquitetônica da plataforma de dados. Fonte: (DEHGHANI, 2019).
- Silos de propriedades super especializados
-
- O terceiro ponto de falha das arquiteturas de dados atuais está relacionado a como são estruturados os times que constroem e mantêm estas plataformas.
- Quando olhamos para as pessoas que operam as plataformas de dados, encontramos engenheiros de dados hiper especializados, isolados das unidades operacionais da organização; onde os dados se originam ou onde são utilizados para tomadas de decisão. Os engenheiros das plataformas de dados não são apenas isolados organizacionalmente, mas também separados e agrupados em uma equipe com base em sua experiência técnica em ferramentas de big data, por exemplo, e muitas vezes sem nenhum conhecimento sobre o negócio.
- Geralmente, o que encontramos em uma empresa são: equipes geradoras de dados desconectadas; consumidores de dados frustrados, lutando por um lugar no topo da lista de pendências (backlog) de uma equipe de dados sobrecarregada. Criamos uma arquitetura e estrutura organizacional que não escala e não entrega o valor prometido: criar uma organização orientada a dados (DEHGHANI, 2019).
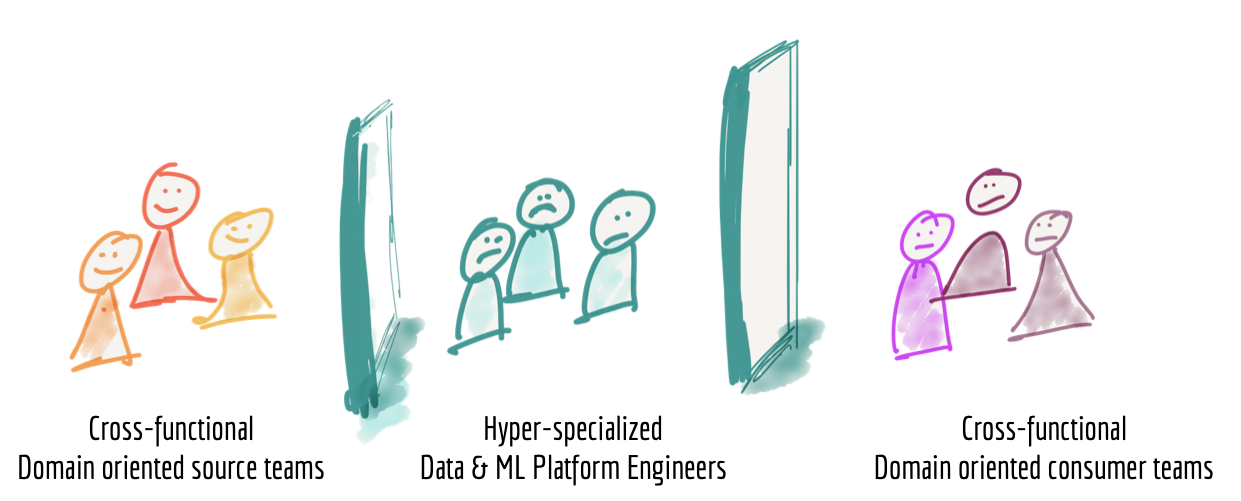
Figura 3: Silos hiper especializados de times de plataforma de dados. Fonte: (DEHGHANI, 2019).
A próxima arquitetura corporativa de plataforma de dados
A nova proposta de arquitetura de plataforma de dados trata a questão da onipresença de dados e fontes por meio do conceito de Data Mesh (malha de dados distribuída).
De acordo com Dehghani (2019), a solução dos problemas das arquiteturas de dados atuais requer uma mudança de paradigma. Dehghani (2019) sugere que a próxima arquitetura de plataforma de dados corporativos esteja na convergência dos conceitos de Arquitetura Distribuída Orientada a Domínio (Distributed Domain Driven Architecture), Design de Plataforma Self-Service (Self-serve Platform Design) e Pensamento em Dados como Produto (Product Thinking with Data).
Decomposição e propriedade de dados orientada a domínio
Para que a plataforma de dados monolítica seja descentralizada, será necessário reverter a forma como pensamos sobre os dados, sua localidade e propriedade. Em vez de transferir os dados dos domínios para um Data Lake ou plataforma de propriedade central, os domínios precisam hospedar e servir seus conjuntos de dados de domínio de maneira facilmente consumível. O armazenamento físico pode ser uma infraestrutura centralizada, como buckets do Amazon S3, mas o conteúdo e a propriedade dos conjuntos de dados devem permanecer com o domínio que os gera (DEHGHANI, 2019).
Dados de domínios orientado à origem
Em uma situação madura e ideal, um sistema de informação e sua equipe ou unidade organizacional não são apenas responsáveis por fornecer requisitos e recursos de negócios, mas também por fornecer as verdades de seu domínio de negócios como conjuntos de dados de domínio de origem (DEHGHANI, 2019).
Na escala corporativa, nunca há um mapeamento de um para um entre um conceito de domínio e um sistema de origem. Muitas vezes existirão muitos sistemas que podem servir partes dos dados que pertencem a um domínio, alguns legados e alguns mais susceptíveis a mudanças. Portanto, podem haver muitos conjuntos de dados alinhados à origem, que precisam ser agregados a um conjunto de dados alinhado ao domínio coeso.
Observe que os conjuntos de dados de domínio devem ser separados dos conjuntos de dados dos sistemas internos. A natureza dos conjuntos de dados de domínio é muito diferente dos dados internos que os sistemas de informação usam para fazer seu trabalho. Eles têm um volume muito maior, representam fatos temporais imutáveis e mudam com menos frequência do que seus sistemas de origem. Por esse motivo, o armazenamento subjacente real deve ser adequado para big data e separado dos bancos de dados operacionais existentes (DEHGHANI, 2019).
Pipelines distribuídos como implementação interna do domínio
A necessidade de limpeza, preparação, agregação e fornecimento de dados permanece, assim como o uso do pipeline de dados. Nesta arquitetura, um pipeline de dados é simplesmente uma complexidade interna e implementação do domínio de dados, sendo tratado internamente dentro do domínio. Como resultado, veremos uma distribuição dos estágios dos pipelines de dados em cada domínio.
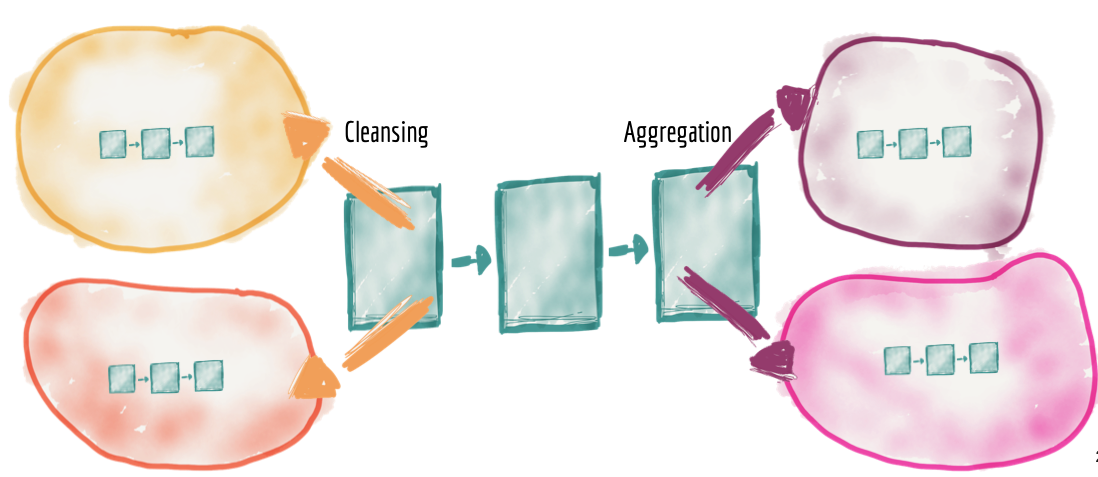
Figura 4: Pipelines distribuídos entre domínios como um detalhe interno de implementação. Fonte: (DEHGHANI, 2019).
Convergência entre dados e product thinking
A distribuição da propriedade dos dados e a implementação de pipelines nas mãos dos domínios de negócios levantam uma preocupação importante sobre acessibilidade, usabilidade e harmonização de conjuntos de dados distribuídos.
Para que uma plataforma de dados distribuídos seja bem-sucedida, as equipes de dados de domínio devem aplicar o pensamento de produto (Product Thinking) com rigor semelhante aos conjuntos de dados que fornecem; considerando seus ativos de dados como seus produtos e os outros cientistas/engenheiros de dados da organização como seus clientes (DEHGHANI, 2019).
Para prover a melhor experiência aos consumidores de dados, os produtos de dados de domínio precisam possuir as seguintes qualidades básicas (DEHGHANI, 2019):
- Detectável: um produto de dados precisa ser facilmente localizável. Uma implementação comum é ter um registro, um catálogo de dados, de todos os produtos de dados disponíveis com suas meta-informações, como seus proprietários, fonte de origem, linhagem, conjuntos de dados de amostra, etc.
- Endereçável: um produto de dados, uma vez descoberto, deve ter um endereço exclusivo seguindo uma convenção global que ajude seus usuários a acessá-lo programaticamente.
- Confiável e verdadeiro: Ninguém vai usar um produto que eles não podem confiar. A realização de limpeza de dados e testes automatizados de integridade no ponto de criação do produto de dados são algumas das técnicas a serem utilizadas para fornecer um nível aceitável de qualidade. Fornecer proveniência e linhagem de dados como metadados associados a cada produto ajuda os consumidores a ganhar mais confiança de sua adequação às suas necessidades específicas. Cada produto de dados deve definir e garantir o nível de sua integridade e veracidade por meio de um conjunto de SLOs (Service Level Objectives).
- Alto descritivo: Produtos de qualidade não requerem a manipulação do consumidor para serem usados: eles podem ser descobertos, compreendidos e consumidos de forma independente. Construir conjuntos de dados como produtos com o mínimo de atrito para os usuários (engenheiros e cientistas de dados) requer semântica e sintaxe bem descritas, idealmente acompanhadas de conjuntos de dados de amostra.
- Interoperável: A chave para possibilitar a correlação eficaz de dados entre domínios é seguir certos padrões e regras de harmonização. Tais padronizações devem pertencer a uma governança global, para permitir a interoperabilidade entre os conjuntos de dados de domínio. As preocupações comuns de tais esforços de padronização são a formatação do tipo de campo, a identificação de polissemia (multiplicidade de sentidos) em diferentes domínios, convenções de endereço, campos de metadados comuns, etc. Por exemplo, em uma área de negócio de streaming de mídia, um 'artista' pode aparecer em diferentes domínios e ter diferentes atributos e identificadores em cada domínio. Uma abordagem é considerar 'artista' com uma entidade federada e um identificador de entidade federada global único para o 'artista', de forma semelhante à forma como identidades federadas são gerenciadas. Interoperabilidade e padronização das comunicações, governadas globalmente, é um dos pilares fundamentais para a construção de sistemas distribuídos.
- Seguro e governado por um controle de acesso global: Acessar conjuntos de dados de produtos com segurança é uma obrigação, quer a arquitetura seja centralizada ou não. No mundo dos produtos de dados orientados a domínios descentralizados, o controle de acesso deve ser aplicado em uma granularidade mais fina, para cada produto de dados de domínio.
Equipes multifuncionais
Equipes responsáveis por domínios (áreas de negócio) responsáveis pelo fornecimento de dados como produtos, precisam contar com novos conjuntos de habilidades: (a) o proprietário do produto de dados e (b) engenheiros de dados.
Um proprietário de produto de dados toma decisões em torno da visão e do roadmap para os produtos de dados, preocupa-se com a satisfação de seus consumidores e mede e aprimora continuamente a qualidade e a riqueza dos dados que seu domínio possui e produz. É responsável pelo ciclo de vida dos conjuntos de dados do domínio, buscando um equilíbrio entre as necessidades concorrentes dos consumidores de dados do domínio (DEHGHANI, 2019).
Para construir e operar os pipelines de dados internos dos domínios, as equipes devem incluir engenheiros de dados. Um efeito colateral vantajoso dessa equipe multifuncional é o compartilhamento de habilidades entre os membros da equipe. Observa-se em algumas situações do mundo real que alguns engenheiros de dados, embora competentes no uso das ferramentas da sua área de atuação, carecem de práticas concernentes à engenharia de software, como entrega contínua e testes automatizados, por exemplo, quando se trata de construir ativos de dados. Da mesma forma, os engenheiros de software que estão construindo sistemas de informação geralmente não têm experiência na utilização de soluções de engenharia de dados (DEHGHANI, 2019).
Os dados devem ser tratados como uma peça fundamental de qualquer ecossistema de software, portanto, engenheiros e generalistas de software devem adicionar a experiência e o conhecimento do desenvolvimento de produtos de dados ao seu cinto de ferramentas.
Convergência de design de plataforma de dados self-service
A construção de infraestruturas comuns como plataforma é um problema bem compreendido e resolvido, embora reconhecidamente as ferramentas e técnicas não sejam tão maduras para ecossistemas de dados.
A utilização de recursos de infraestrutura agnóstica a domínio a partir de uma plataforma de infraestrutura de dados resolve a necessidade de duplicar o esforço de configurar mecanismos de pipeline de dados, armazenamento e infraestrutura de streaming. Neste sentido, uma equipe de infraestrutura de dados deve fornecer a tecnologia necessária que os domínios precisam para capturar, processar, armazenar e disponibilizar seus produtos de dados (DEHGHANI, 2019).
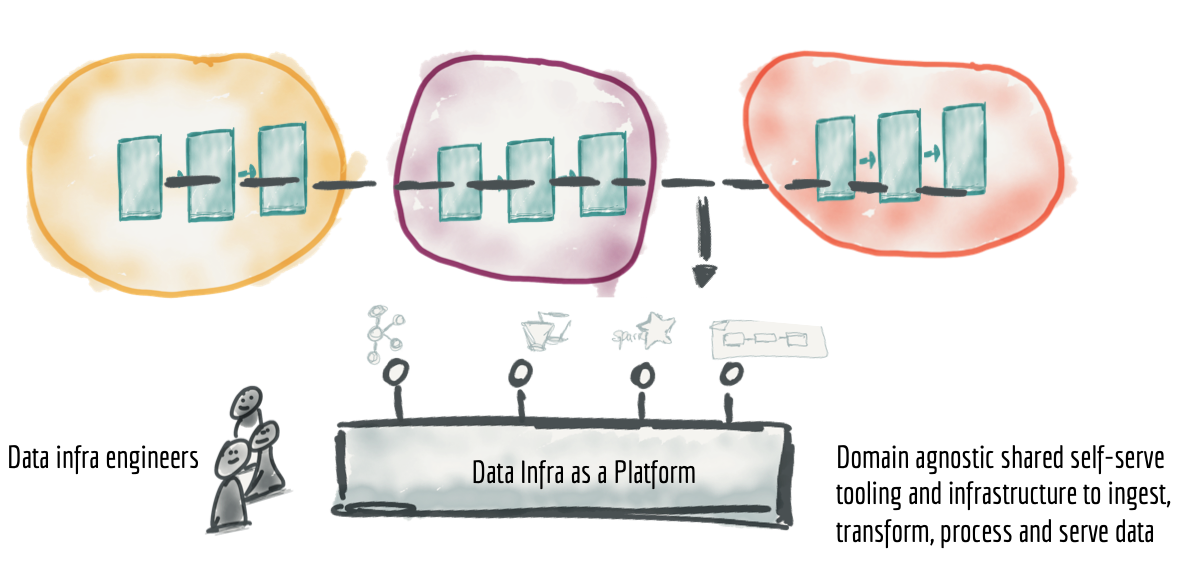
Figura 5: Plataforma de infraestrutura de dados agnóstica a domínio. Fonte: (DEHGHANI, 2019).
A chave para construir uma infraestrutura de dados como plataforma é: (a) não incluir nenhum conceito específico de domínio ou lógica de negócios, mantendo-a agnóstica de domínio, e (b) certificar-se de que a plataforma oculte toda a complexidade subjacente e forneça os componentes de infraestrutura de dados em uma forma self-service (DEHGHANI, 2019).
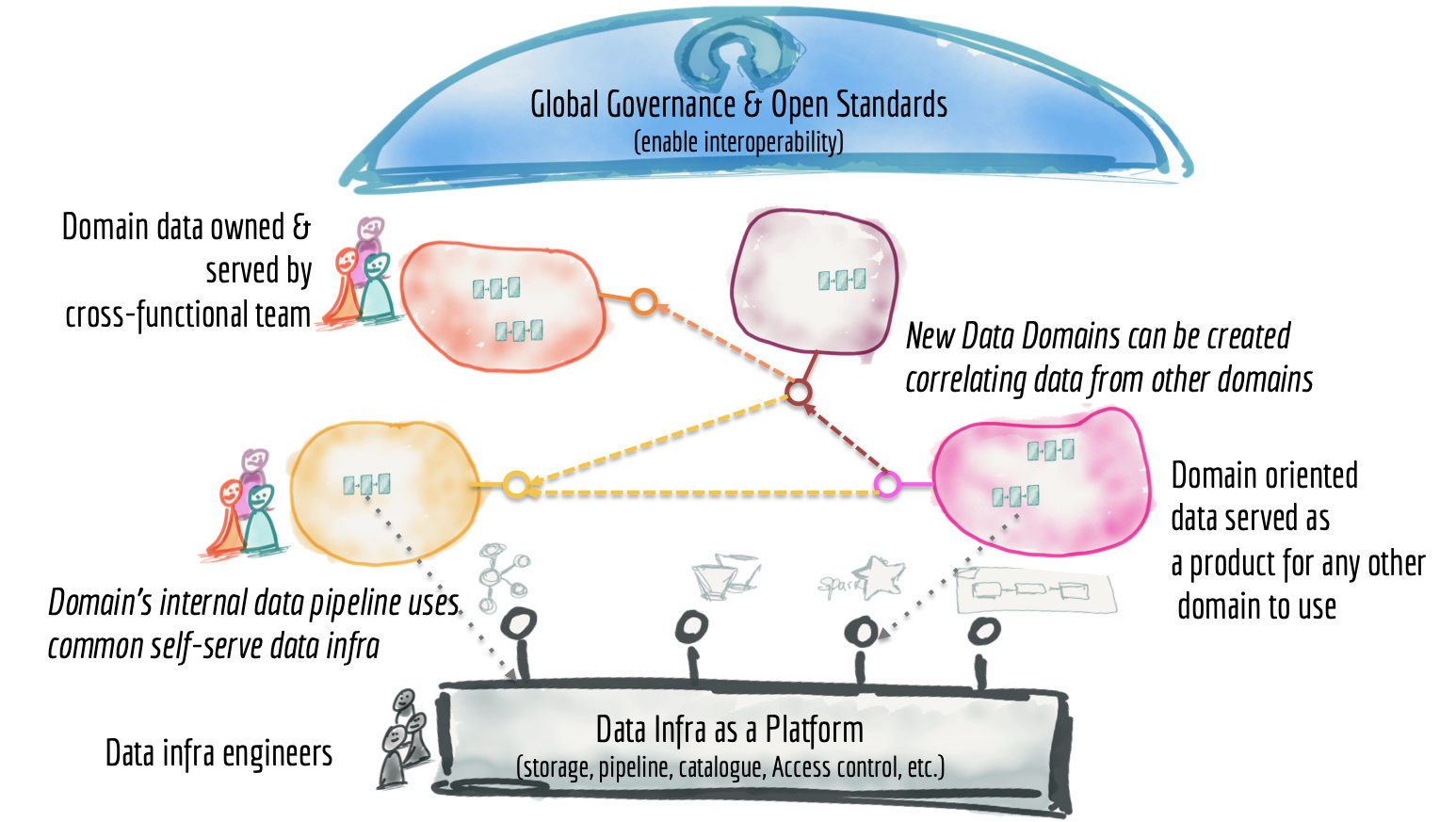
Figura 6: Visão de altíssimo nível de uma arquitetura de Data Mesh. Fonte: (DEHGHANI, 2019).
Você deve estar se perguntando onde o Data Lake ou o Data Warehouse se encaixam nesta arquitetura. Eles são simplesmente nós na malha. É muito provável que não precisemos de um Data Lake, porque os logs distribuídos e os dados originais de sistemas estão disponíveis para exploração de diferentes conjuntos de dados imutáveis endereçáveis como produtos. No entanto, nos casos em que precisamos fazer alterações no formato original dos dados para exploração adicional, como rotulagem, o domínio com essa necessidade pode criar seu próprio Data Lake ou Data Warehouse (DEHGHANI, 2019).
A principal mudança é tratar o produto de dados de domínio como uma preocupação de primeira classe e as ferramentas e o pipeline de Data Lake / Data Warehouse como uma preocupação de segunda classe - um detalhe de implementação. Isso inverte o modelo mental atual de um Data Lake / DW centralizado para um ecossistema de produtos de dados que funcionam juntos, uma malha de dados (DEHGHANI, 2019).
Data Hub
De acordo com o Goasduff (2020), Data Hubs são “hubs” conceituais, lógicos e físicos para mediação da semântica, em suporte à governança e compartilhamento de dados entre sistemas. Data Hubs possibilitam o fluxo contínuo de dados devidamente governados.
Para o DAMA (2017), existem diferentres tipos de Data Hubs, uma vez que este é um conceito que objetiva a consolidação e o provimento de dados consistentes tanto para outros sistemas quanto diretamente para para humanos. Neste sentido, DAMA (2017) menciona que Data Warehouses e soluções de Gestão de Dados Mestres são tipos de Data Hubs.
Segundo Harrad (2020), o Data Hub é o local ideal para os dados principais de uma organização. Ele centraliza os dados que são críticos entre os aplicativos e permite o compartilhamento contínuo entre diversos endpoints, ao mesmo tempo em que é a principal fonte de dados confiáveis para a iniciativa de governança de dados. Os Data Hubs fornecem Dados Mestres para aplicativos e processos corporativos. Eles também são usados para conectar aplicativos de negócios a estruturas analíticas, como data warehouses e data lakes.
 Figura 1: Data Hub como pilar principal de dados governados. Fonte: HADDAD (2020).
Figura 1: Data Hub como pilar principal de dados governados. Fonte: HADDAD (2020).
Diferentemente de Data Warehouses e Data Lakes, que são focados no provimento de dados para finalidades analíticas, os Data Hubs servem como pontos de mediação e compartilhamento de dados, com o foco em governança (HARRAD, 2020).
Data warehouses, Data Lakes e Data Hubs não são alternativas intercambiáveis, mas sim complementares. Juntos podem apoiar iniciativas baseadas em dados e transformação digital. A tabela abaixo resume suas semelhanças e diferenças HARRAD (2020):
|
Data Hub |
Data Warehouse |
Data Lake |
|
|
Uso primário |
Processos operacionais |
Análise e relatórios |
Análise, relatórios e Machine Learning. |
|
Formato dos dados |
Estruturados |
Estruturados |
Estruturados e não estruturados |
|
Governança de Dados |
Pilar principal para todas as regras de aplicação de governança de dados |
Governança pós-fato, pois consome dados operacionais existentes |
Abordagem de dados “Use por sua conta e risco”. Pouco governado |
|
Qualidade de Dados |
Altíssima qualidade |
Alta qualidade |
Média e baixa qualidade |
|
Integração com aplicações |
Integração bidirecional em tempo real com processos de negócios existentes por meio de APIs. |
ETL monodirecional em lote. Os dados transformados e limpos são atualizados em baixa frequência (por hora, diariamente ou semanalmente) |
ETL ou ELT monodirecional em lote. Os dados são despejados sem controle, assumindo uma limpeza futura pelo consumidor |
|
Interação com usuários de negócio |
Pode ser a fonte primária de autoria de elementos-chave de dados, como Dados Mestre e Dados de Referência. Expõe interfaces amigáveis para criação de dados, administração de dados e pesquisa. |
Oferece acesso somente leitura a dados limpos e preparados, por meio de relatórios, painéis analíticos ou consultas ad-hoc. |
Requer limpeza/preparação de dados antes do consumo. O acesso aos usuários corporativos é oferecido principalmente por meio de relatórios, painéis ou consultas ad-hoc. Usado para preparar conjuntos de dados de aprendizado de máquina. |
|
Processos Operacionais da organização |
Repositório principal para dados confiáveis expostos em processos de negócios. Pode ser o principal condutor dos processos de negócios corporativos. |
Serve principalmente para processos de análise. |
Atende principalmente processos de Machine Learning. |
Integração e Governança de Dados
A necessidade de gerenciar a complexidade, juntamente com os seus custos decorrentes, são os motivos para arquitetar a integração de dados em uma perspectiva corporativa. Um projeto corporativo de integração de dados é comprovadamente mais eficiente e econômico do que soluções distribuídas ou ponto a ponto, visto que o desenvolvimento de soluções ponto a ponto entre sistemas pode acabar sobrecarregando até mesmo os recursos de suporte de TI mais eficientes (DAMA, 2017).
Data Hubs, como Data Warehouses e soluções de Gestão de Dados Mestres auxiliam na minimização de tais problemas por meio da consolidação e provimento de dados consistentes para usuários e outros sistemas. Da mesma forma, a complexidade do gerenciamento de dados operacionais e transacionais que precisam ser compartilhados em toda a organização pode ser bastante simplificada por meio da utilização de técnicas de integração de dados corporativos, como integração hub-and-spoke e modelos de mensagens canônicas (DAMA, 2017).
Sabe-se que Integração e interoperabilidade de dados é algo crítico para Data Warehousing e Business Intelligence, bem como para a Gestão de Dados Mestres e de Referência, visto que esses tópicos concentram-se na transformação e integração de dados de sistemas de origem para Data Hubs (hubs de dados) consolidados, e destes para sistemas de destino, de onde os dados podem ser entregues tanto para outros sistemas quanto diretamente para para humanos (DAMA, 2017).
O modelo hub-and-spoke de Data Hub mostra-se como uma alternativa às integrações do tipo ponto-a-ponto. Este modelo consolida dados compartilhados (fisicamente ou virtualmente) em um hub de dados central em que muitos aplicativos podem utilizar. Deste modo, todos os sistemas que desejam trocar dados o fazem por meio de um sistema central comum de controle de dados, em vez de diretamente entre si (ponto a ponto).
Os Enterprise Service Buses (ESB) constituem um tipo de solução de integração para compartilhamento de dados quase em tempo real entre vários sistemas, onde o hub é um conceito virtual do formato padrão ou do modelo canônico para compartilhamento de dados na organização.
Uma arquitetura hub-and-spoke nem sempre pode ser a melhor solução. A latência ou o desempenho do modelo pode às vezes não ser adequada para a necessidade. O próprio hub cria sobrecarga em uma arquitetura hub-and-spoke. Uma solução ponto a ponto não exigiria o hub, no entanto, os benefícios do mesmo superam as desvantagens da sobrecarga assim que três ou mais sistemas estão envolvidos no compartilhamento de dados. O uso do padrão de design hub-and-spoke para o intercâmbio de dados pode reduzir drasticamente a proliferação de soluções de integração e transformação de dados e, assim, simplificar massivamente o suporte organizacional necessário (DAMA, 2017).
Qualidade de Dados
Existe uma percepção incorreta de que a qualidade de dados esteja estritamente relacionada com os seus aspectos estruturais. A qualidade de dados deve ser analisada em diversos aspectos, dos quais, muitos não estão diretamente relacionados à forma física do dado, mas ao seu entorno (BARBIERI, 2019).
Barbieri (2019) comenta que há vários autores com variadas classificações de dimensões de qualidade de dados. Abaixo são listadas algumas das dimensões mais usualmente encontrados na literatura:
- Completude: Se falta algum atributo de dados do seu registro, como CEP no endereço, não há completude;
- Unicidade: Se existem dois funcionários com o mesmo CPF, por exemplo, há problemas de unicidade;
- Razoabilidade: Se a data da receita médica é posterior à data preenchida de compra do medicamento na farmácia, por exemplo, não há razoabilidade;
- Integridade: Se o mesmo dado possui valores diferentes em locais distintos, não há integridade;
- Temporalidade: Esta característica define a necessidade do dado estar disponível no tempo exigido e na forma demandada. Por exemplo, a marcação de um assento de voo deverá ocorrer em tempo real para que a sua disponibilidade seja garantida;
- Validade: Está relacionada com a forma estrutural estabelecida. Por exemplo, se o código de CEP é válido e estão listados nos dados de referência. Se o tipo de dado definido está sendo obedecido, etc.;
- Cobertura: Dimensão de qualidade que considera o quanto os dados disponíveis atendem, por exemplo, geograficamente, aos seus objetivos. Ex. tenho todos os dados relativos ao Brasil, mas pretendo atuar na Argentina;
- Precisão: Dimensão de qualidade relativa à precisão do dado cadastrado. Ex: Moro no bairro centro, mas o CEP cadastrado é da pampulha.
Com a evolução da ciência de dados, outros aspectos, como privacidade e ética, passarão a ser considerados dentro dos aspectos de qualidade.
Kimball e Ross (2013) pontuam que iniciativas puramente técnicas para solucionar problemas de qualidade de dados geralmente não funcionam, a não ser que façam parte de uma cultura geral de qualidade, estabelecida pela alta cúpula da instituição. Deste modo, Kimball e Ross (2013) afirmam que problemas com qualidade de dados não podem ser solucionados apenas pela TI. Em muitos casos, na realidade, problemas com qualidade de dados nada tem haver com TI.
Linhagem de Dados
De acordo com Kimball e Ross (2013), a linhagem de dados descreve as origens e as etapas de processamento que produziram cada elemento de dado em uma tabela. Esta linhagem deve ser armazenada no Data Warehouse / Data Lake por meio dos metadados associados a cada elemento. Essa linhagem é explicitamente exigida por certos requisitos de conformidade, mas deve fazer parte de todas as situações de arquivamento.
Segundo Barbieri (2019), Linhagem de Dados significa o entendimento de cada passo ao longo dos processos, observando quais dados e metadados entraram em cada bloco de processamento, quais dados saíram, quais foram os processamentos efetuados, regras aplicadas, etc. Deste modo, quando houver um problema específico no fluxo de processamento de dados, a linhagem poderá auxiliar na depuração e identificação do problema. Conhecer os detalhes deste caminho é fundamental para a depuração de erros que possam surgir em um ponto mais adiante do fluxo, mas que podem ter sido produzidos em estágios anteriores.
 Figura 1: Exemplo de visualização de um grafo de exibição de linhagem de dados.
Figura 1: Exemplo de visualização de um grafo de exibição de linhagem de dados.
ETL
De acordo com Kimball e Ross (2010), ETL (Extract, Transform, Load) consiste em um paradigma padrão para a aquisição e preparação de dados, de modo a torná-los prontos para exposição a ferramentas de Business Intelligence (BI). O processo de ETL preenche a lacuna entre os dados fonte dos sistemas transacionais de produção e a camada de apresentação e schemas dimensionais necessários para o consumo por ferramentas de BI. É um trabalho pesado, que consome cerca de 70% do tempo necessário para a construção de ambientes de Business Intelligence.
O sistema de ETL agrega valor aos dados com as tarefas de limpeza e conformidade, alterando os dados e aprimorando-os. Além disso, essas atividades podem ser arquitetadas para criar metadados de diagnóstico, eventualmente levando à reengenharia de processos de negócios para melhorar a qualidade dos dados nos sistemas de origem ao longo do tempo (Kimball e Ross, 2013).
Staging Area
De acordo com Kimball e Ross (2010), Staging Area é o local onde os dados fontes são transformados em dados com significados, prontos para serem apresentados aos usuários finais. Este processo precisa ser capaz de transformar, eficientemente, dados brutos em dados de valor, acomodados em um modelo objetivo, minimizando a movimentação desnecessária.
Neste mesmo sentido, DAMA (2017) define Staging Area como uma área intermediária de armazenamento, entre os dados originais e o repositório centralizado. Nesta área, os dados são transformados, integrados e preparados para o carregamento no Data Warehouse.
EDW e Modelagem Dimensional
Modelagem Dimensional
Modelagem dimensional é uma disciplina de design que abrange a modelagem relacional formal e a engenharia de realidades textuais e numéricas. Comparada à terceira forma normal da Modelagem Entidade-Relacionamento, é menos rigorosa (permitindo ao designer mais discrição na organização das tabelas), porém mais prática pois acomoda a complexidade de um banco de dados enquanto contribui para a melhoria do seu desempenho. A modelagem dimensional possui um portfólio extenso de técnicas para lidar com situações do mundo real (KIMBALL e ROSS, 2010).
Devido a sua simplicidade na apresentação dos dados, a modelagem dimensional tem sido amplamente aceita como a técnica dominante de modelagem de Data Warehouses. A simplicidade é a chave fundamental que permite aos usuários finais navegarem com eficiência sobre os dados apresentados pelo DW. Ao focar consistentemente em uma perspectiva orientada para os negócios, recusando-se a comprometer a objetivos específicos de usuários, você estabelece um design coerente que atende às necessidades analíticas da organização (KIMBALL e ROSS, 2013).
O modelo dimensional deve corresponder à estrutura física dos eventos de captura de dados. Um modelo não deve ser elaborado para atender a um relatório em específico (report-of-the-day). Os processos de negócios de uma empresa ultrapassam as fronteiras dos departamentos e funções organizacionais. Em outras palavras, você deve construir uma única tabela de fatos para métricas de vendas atômicas em vez de preencher bancos de dados / tabelas semelhantes, mas ligeiramente diferentes, contendo métricas de vendas para as equipes de vendas, marketing, logística e finanças separadamente (KIMBALL e ROSS, 2013).
Medições e Contexto
A modelagem dimensional se inicia dividindo o mundo entre medições e contexto. Medições são usualmente numéricas e tomadas repetidamente. Medições numéricas são fatos. Fatos estão sempre cercados geralmente por contexto textuais, que são verdadeiros no momento em que os fatos são gerados. Fatos são constituídos de atributos numéricos, muito específicos e bem definidos. Em contraste, o contexto que cerca os fatos é aberto e verboso (KIMBALL e ROSS, 2010).
Embora possamos aglomerar todo o contexto juntamente com cada medida em um vasto e único registro lógico, veremos que, geralmente, é mais conveniente separar o contexto em grupos independentes. Quando armazenados fatos -- vendas em reais de uma mercearia referentes a um produto específico, por exemplo -- naturalmente dividiremos o contexto entre grupos denominados Nome do Produto, Loja, Horário, Cliente, Balconista, dentre outros. Chamamos esses agrupamentos lógicos de dimensões, e assumimos informalmente que essas dimensões são independentes. A figura abaixo mostra um modelo dimensional para um armazenamento típico de fatos para uma mercearia (KIMBALL e ROSS, 2010).
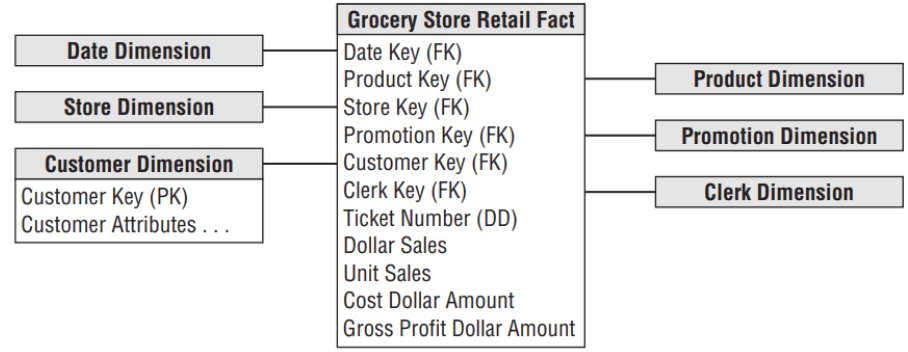
Na realidade, dimensões são raramente independentes dentro de um contexto estatístico. No exemplo da mercearia, cliente (customer) e loja (store) terão claramente uma correlação estatística. Mas é usualmente uma decisão correta separar cliente e loja em dimensões separadas. Uma única dimensão combinada provavelmente seria difícil de manejar, com dezenas de milhões de linhas. O registro de onde um cliente comprou em determinada loja é expressado mais naturalmente em uma Tabela Fato, que mostra também quando isso ocorreu (dimensão tempo) (KIMBALL e ROSS, 2010).
Assumir a independência de dimensões significa que todas as dimensões, como produto, loja e cliente são independentes do fator tempo. Mas devemos levar em conta a mudança lenta e esporádica dessas dimensões ao longo do tempo. De fato, como mantenedores do Data Warehouse, assumimos o compromisso de representar essas mudanças. Esta situação dá origem à técnica denominada Slowly Changing Dimensions (SCD) (KIMBALL e ROSS, 2010).
Relacionando os dois Mundos da Modelagem
Modelos dimensionais são modelos relacionais, em que Tabelas Fato estão na terceira forma normal e as Tabelas de Dimensão estão na segunda forma normal, confusamente chamadas de desnormalizadas. Lembre-se que a grande diferença entre a segunda e a terceira forma normal é que os valores repetidos (redundantes) são removidos da segunda forma normal por meio da criação de novas tabelas (snowflake). O fato de removermos os valores de dimensão da Tabela Fato, e colocando esses valores em suas próprias tabelas, coloca a Tabela Fato na terceira forma normal (KIMBALL e ROSS, 2010).
Devemos resistir ao impulso de colocar as tabelas de dimensão na terceira forma normal (snowflake), pois tabelas únicas (flat) são muito mais eficientes para recuperação de dados por meio de instruções SQL. Em particular, os atributos de dimensão com muitos valores repetidos são alvos perfeitos para índices de bitmap. Colocar uma dimensão na terceira forma normal (snowflaking), embora não seja incorreto, elimina a possibilidade de utilização de índices de bitmap e aumenta a percepção de complexidade no design (KIMBALL e ROSS, 2010).
Lembre-se que na área de apresentação de um DW não precisamos nos preocupar em forçar a aplicação de regras de dados muito rígidas, exigindo dimensões snowflaked (terceira forma normal). A garantia de integridade já é garantida no estágio de ETL (staging ETL system) (KIMBALL e ROSS, 2010).
Arquitetura de Barramento do Enterprise Data Warehouse
A arquitetura de barramento do Enterprise Data Warehouse (Enterprise Data Warehouse Bus Architecture) fornece uma abordagem incremental para construir o sistema de DW/BI corporativo. Essa arquitetura decompõe o processo de planejamento de DW/BI em partes gerenciáveis, concentrando-se nos processos de negócios, enquanto oferece integração por meio de dimensões padronizadas que são reutilizadas em todos os processos. Ela fornece uma estrutura de arquitetura, ao mesmo tempo em que decompõe o programa para incentivar implementações ágeis gerenciáveis correspondentes às linhas na matriz de barramento do EDW (KIMBALL e ROSS, 2013).
Ao definir uma interface de barramento padrão para o ambiente DW/BI, modelos dimensionais separados podem ser implementados por diferentes grupos em momentos diferentes. Deste modo, as áreas de negócio distintas podem se conectar e coexistirem de maneira complementar.
Como ilustrado pelo diagrama abaixo, podemos vislumbrar diversos processos de negócio plugados em um barramento comum. Cada processo da cadeia de valor de uma organização pode exigir a criação de uma família de modelos dimensionais, que compartilham uma série de dimensões conformadas.
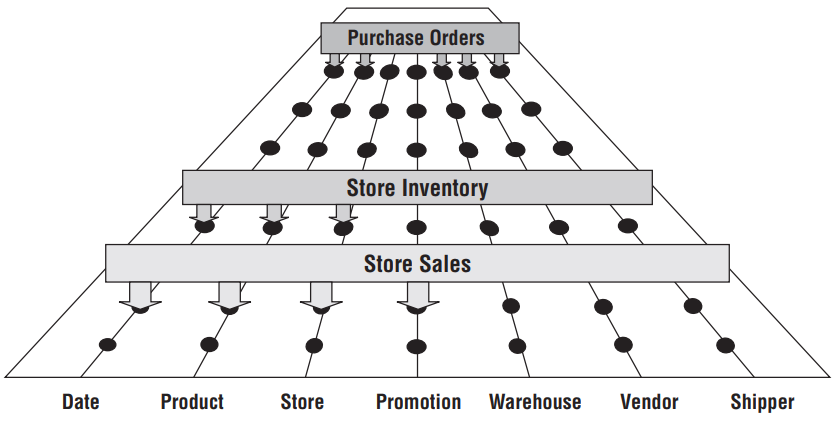
Sem a definição de uma matriz de barramento, algumas equipes de DW/BI caem na armadilha de usar técnicas ágeis para criar rapidamente soluções isoladas (relatórios e dashboards). Na maioria das situações, a equipe atua com um pequeno conjunto de usuários para extrair um conjunto limitado de dados de origem e disponibilizá-los para resolver seus problemas exclusivos. O resultado geralmente é um canal de dados autônomo que outros não podem aproveitar, ou pior ainda, fornece dados que não estão vinculados às outras informações analíticas da organização. Incentivamos a agilidade, quando apropriado, mas a construção de conjuntos de dados isolados deve ser evitada (KIMBALL e ROSS, 2013).
Matriz de Barramento
A matriz de barramento do Enterprise Data Warehouse (Enterprise Data Warehouse Bus Matrix) é uma ferramenta essencial para projetar e comunicar a arquitetura de barramento do EDW. Como pode ser visto na imagem abaixo, as linhas da matriz são processos de negócios e as colunas são dimensões. As células marcadas da matriz indicam se uma dimensão está associada a um determinado processo de negócios. A equipe de design verifica cada linha para testar se uma dimensão candidata está bem definida para o processo de negócios e também verifica cada coluna para ver onde uma dimensão deve ser conformada em vários processos de negócios. Além das considerações de projeto técnico, a matriz de barramento é usada como entrada para priorizar projetos de DW/BI com gestão de negócios, pois as equipes devem implementar uma linha da matriz por vez (KIMBALL e ROSS, 2013).
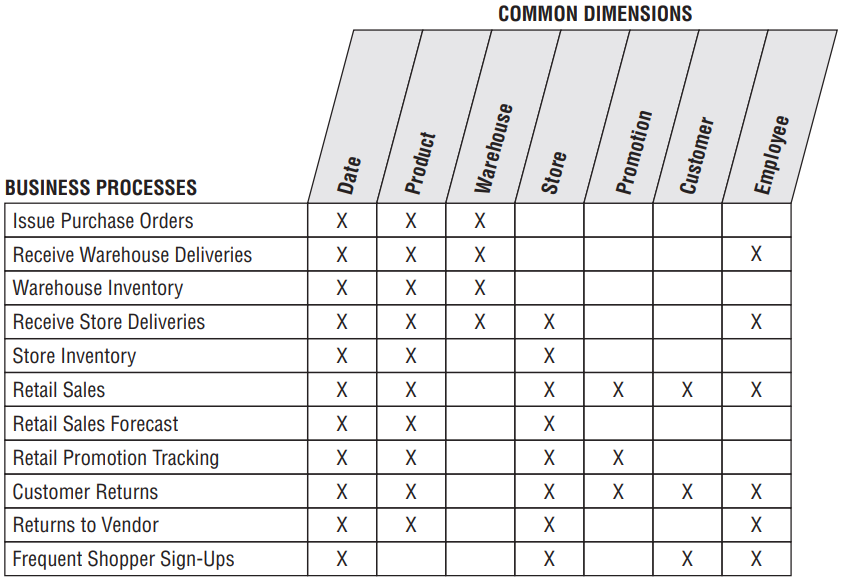
Tabela Fato
Tabelas Fato são tabelas para armazenamento de medidas. A maioria das medidas armazenadas em Tabelas Fato dizem respeito a séries temporais, em que são armazenados timestamps e chaves estrangeiras conectando a dimensões de data calendário.
Cada linha em uma Tabela Fato corresponde a um evento de medição. A ideia de que um evento de medição no mundo físico tem um relacionamento de um para um com uma única linha na tabela de fatos correspondente é um princípio fundamental para a modelagem dimensional. Todo o resto é construído a partir dessa premissa (KIMBALL e ROSS, 2013).
Tabelas Fato são a figura central de qualquer modelo dimensional. Toda Tabela Fato deve possuir uma única e explícita granularidade definida. A granularidade de uma Tabela Fato deve ser definida durante o processo de modelagem. Kimball e Ross (2010) recomendam que a definição da granularidade (explicitar exatamente o que uma Tabela Fato representa) seja a primeira ação a ser realizada na modelagem de uma Tabela Fato. Podem ser feitas declarações atômicas ou de alto nível, representando agrupamentos e sumarizações. Após definir a granularidade, deve-se então definir precisamente as dimensões possíveis associadas.
Kimball e Ross (2010) recomendam que os detalhes mais atômicos disponíveis nos sistemas de origem devem ser refletidos no DW por meio de Tabelas Fato. Um registro fato (fact record) em um modelo dimensional é criado como uma resposta 1:1 para a medida de um evento em um processo de negócio específico. Tabelas Fato são definidas pela física do mundo real.

Os fatos de uma Tabela Fato devem ser “Verídicos à Granularidade”. Por exemplo, os seguintes fatos são exemplos apropriados para a declaração "line item of a doctor’s bill”:
-
- Date (of treatment)
- Doctor (or provider)
- Patient
- Procedure
- Primary Diagnosis
- Location (such as the doctor’s office)
- Billing Organization (an organization the doctor belongs to)
- Responsible Party (either the patient or the patient’s legal guardian)
- Primary Payer (often an insurance plan)
- Secondary Payer (maybe the responsible party’s spouse’s insurance plan)
Outros fatos, como “Valor cobrado no ano até a data corrente para o paciente para todos os tratamentos” não são Verídicos. Neste caso, quando aplicações de BI combinam registros de fato arbitrariamente, estes Fatos Inverídicos produzem resultados sem sentido e inúteis. Olhando desta maneira, este tipo de fato é perigoso pois induz usuários de negócio a erros. Este tipo de fato agregado deve ser omitido do design do DW e calculado diretamente na aplicação de BI (KIMBALL e ROSS, 2013).
Como os dados de medição são esmagadoramente o maior conjunto de dados, eles não devem ser replicados em vários locais para várias funções organizacionais na organização. Permitir que usuários de negócios de várias organizações acessem um único repositório centralizado para cada conjunto de dados garante o uso de dados consistentes em toda a empresa (KIMBALL e ROSS, 2013).
É teoricamente possível que um fato medido seja textual; no entanto, a condição raramente surge. Na maioria dos casos, uma medida textual é uma descrição de algo e é extraída de uma lista discreta de valores. O designer deve fazer todos os esforços para colocar os dados textuais em dimensões onde possam ser correlacionados de forma mais eficaz com os outros atributos de dimensão textual. Você não deve armazenar informações textuais redundantes em tabelas de fatos. A menos que o texto seja exclusivo para cada linha na tabela de fatos, ele pertence à tabela de dimensão. Um fato de texto verdadeiro é raro porque o conteúdo imprevisível de um fato de texto, como um comentário de texto de forma livre, torna-o quase impossível de ser analisado (KIMBALL e ROSS, 2013).
Tabelas Fato correspondem a medidas resultantes de eventos observáveis, e não a demandas de relatórios específicos (KIMBALL e ROSS, 2013).
Tabela de Dimensão
Tabelas de dimensão são companheiras integrais de Tabelas Fato. Tabelas de dimensão possuem descrições textuais que descrevem o contexto associado à medida realizada pelo processo de negócio. Elas descrevem o “quem, o quê, onde, quando, como e porque”, associado ao evento. Como ilustrado abaixo, tabelas de dimensão geralmente possuem muitos atributos. Não é incomum que uma tabela de dimensão possua de 50 a 100 atributos, embora algumas possuam apenas uma quantidade reduzida (Kimball e Ross, 2013).

Os atributos das dimensões servem como a fonte primária de restrições em consultas, agrupamentos e rótulos para colunas de relatórios. Por exemplo, quando um usuário deseja ver o valor vendido por marca, a coluna “marca” deve estar disponível como um atributo da dimensão associada (Kimball e Ross, 2013).
Os atributos devem consistir em palavras reais em vez de abreviações. Você deve se esforçar para minimizar o uso de códigos em tabelas de dimensão, substituindo-os por atributos textuais mais detalhados. Às vezes, os códigos ou identificadores operacionais têm um significado legítimo de negócio para os usuários, ou são requeridos ao se comunicar com a área operacional. Nestes casos, os códigos devem aparecer como atributos de dimensão explícitos, além dos atributos textuais de fácil interpretação. Códigos operacionais às vezes têm inteligência embutida. Por exemplo, os primeiros dois dígitos podem identificar a linha de negócios, enquanto os próximos dois dígitos podem identificar a região global. Em vez de forçar os usuários a interrogar ou filtrar em substrings dentro dos códigos operacionais, extraia os significados incorporados e apresente-os aos usuários como atributos de dimensão separados que podem ser facilmente filtrados, agrupados e reportados (Kimball e Ross, 2013).
Kimball e Ross (2013) mostram que quanto mais granular é o dado, maior a sua dimensionalidade. Deste modo, o dado deve ser armazenado em um DW em sua menor granularidade e maior número de dimensões possíveis. Isso deve ser feito para que o usuário de negócio tenha a maior gama possível de possibilidades de filtros e agrupamentos na elaboração de relatórios ad-hoc.
Embora seja aceitável, relacionamentos entre dimensões devem ser evitados. Na maioria dos casos, as correlações entre dimensões (Outrigger Dimensions) devem ser denotadas por meio de Tabelas Fato (Kimball e Ross, 2013).
Quando as dimensões são separadas, alguns designers desejam criar uma pequena tabela com apenas as duas chaves de dimensão para mostrar a correlação sem usar a tabela de fato. Em muitos cenários, essa tabela bidimensional é desnecessária. Não há razão para evitar a tabela fato para responder a esta consulta de relacionamento. As tabelas fato são incrivelmente eficientes porque contêm apenas chaves de dimensão e medições, juntamente com a dimensão degenerada ocasional. A tabela fato é criada especificamente para representar as correlações e os relacionamentos muitos para muitos entre as dimensões (Kimball e Ross, 2013).
Star Schema
Agora que você entende as Tabelas Fato e Dimensões, é hora de reunir os blocos de construção em um modelo dimensional, conforme mostrado na figura abaixo. Cada processo de negócio é representado por um modelo dimensional que consiste em uma Tabela Fato contendo os dados numéricos do evento medido, cercada por um grupo de tabelas de dimensão, com o contexto que era verdadeiro no momento em que o evento ocorreu. Essa estrutura característica em forma de estrela costuma ser chamada de junção em estrela (Star Join) (KIMBALL e ROSS, 2013).
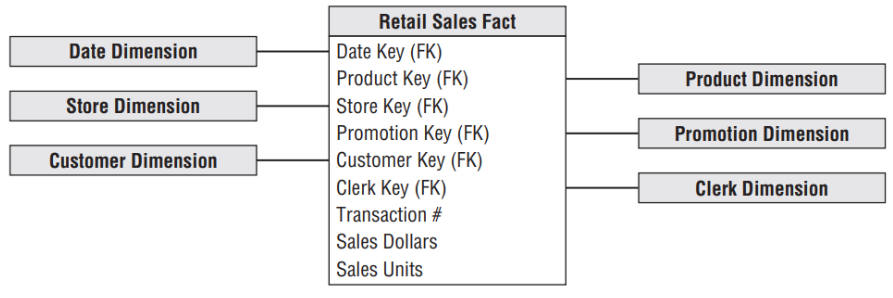
Tabela Fato sem Fato
Tabela Fato sem fato (Factless Fact Tables) são Tabelas Fato que não possuem nada além de chaves estrangeiras para dimensões. O primeiro tipo de Factless Table diz respeito a uma tabela que armazena eventos. Diversas Tabelas Fato para rastreamento de eventos tornam-se Tabelas Fato sem fato. Um exemplo seria uma Tabela Fato para armazenar atendimentos a estudantes em uma faculdade, como pode ser visto na figura abaixo:
Esse tipo de tabela torna-se uma Tabela Fato sem fato, pois não existem fatos óbvios gerados a cada atendimento de um estudante. Devido a ausência de fatos, e no intuito de melhorar a legibilidade de instruções SQL sobre esse tipo de tabela, alguns engenheiros de dados optam por incluir um fato fictício ao final da tabela, com valor constante 1, por exemplo, “atendimento”.
Um segundo tipo de Tabela Fato sem fato é denominado tabela de cobertura (coverage table). Uma tabela de cobertura típica é mostrada abaixo:
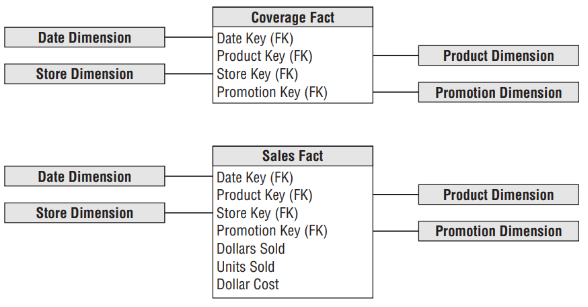
Tabelas de cobertura são frequentemente necessárias quando as Tabelas Fato principais são esparsas. A figura acima mostra também uma tabela de vendas (Sales Fact) que armazena as vendas de produtos em lojas em dias particulares, sob condições diversas de promoção. A Tabela Fato principal responde diversas perguntas de negócio interessantes, mas não pode dizer nada sobre coisas que não ocorreram. Por exemplo, não pode responder perguntas como: “Quais produtos estavam em promoção, mas não venderam?”, pois a tabela possui apenas produtos que foram vendidos (Kimball e Ross, 2013).
Tabela Fato de Snapshot Periódico
Uma linha em uma Tabela Fato de Snapshot Periódico (Periodic Snapshot Fact Table) sumariza diversas medidas de eventos ocorridos sobre um período pré-definido, como um dia, uma semana, ou um mês. Neste caso, o grão é o período, não a transação individual. Este tipo de tabela possui muitos fatos porque qualquer evento de medição consistente com a granulação da tabela de fatos é permitido. São tabelas geralmente uniformemente densas em suas chaves estrangeiras, pois mesmo que nenhuma atividade tenha ocorrido no período, uma linha é tipicamente inserida para cada fato, contendo zero ou null (Kimball e Ross, 2013).
Fatos Conformados
Se a mesma medida aparece em diferentes Tabelas Fato, deve ser tomado o devido cuidado para que as definições técnicas dos fatos sejam idênticas. Se fatos separados são consistentes, tais fatos conformados devem possuir a mesma nomenclatura. Mas se os fatos são incompatíveis, eles devem possuir nomenclaturas diferentes, que servirão como alerta aos usuários de negócio (Kimball e Ross, 2013).
Chaves Dimensionais
Se fatos são medidas reais geradas rapidamente, concluímos que Tabelas Fato criam uma situação de relacionamento muitos-para-muitos (M:N) entre as dimensões. Muitos clientes compram muitos produtos em diversas lojas em diversos momentos (KIMBALL e ROSS, 2010).
Deste modo, modelamos as medidas como Tabelas Fato com diversas chaves estrangeiras (Foreign Key - FK), referenciando as entidades de contexto (dimensões). E as tabelas de dimensões (entidades de contexto) possuem, cada uma, a sua chave primária (Primary Key - PK) (KIMBALL e ROSS, 2010).
Uma Tabela Fato em um modelo dimensional Star Schema é constituída, além das medidas, por múltiplas FKs, cada uma pareada com a chave primária em uma dimensão. Note que este design possibilita às tabelas de dimensão possuírem chaves primárias não existentes na Tabela Fato. Esta situação é consistente com a manutenção da integridade referencial e apropriada para a modelagem dimensional (KIMBALL e ROSS, 2010).
No mundo real, existem diversas razões convincentes para a construção de pares FK-PK como chaves substitutas (Surrogate Keys), que são apenas números inteiros sequenciais. É um grande erro definir chaves em um DW com base em chaves naturais (Natural Keys), provenientes das fontes operacionais (KIMBALL e ROSS, 2010).
Ocasionalmente, uma medida perfeitamente válida poderá envolver alguma dimensão ausente. Talvez, em algumas situações, um produto poderá ser vendido a um cliente por meio de uma transação sem uma loja definida. Neste caso, ao invés de armazenarmos null na FK de loja, podemos manter um registro especial na dimensão loja, com o valor “No Store”, e utilizá-lo para esta finalidade, por exemplo (KIMBALL e ROSS, 2010).
Logicamente, uma Tabela Fato não precisa de uma chave primária. Dependendo da situação, duas observações legítimas poderão ser representadas de forma idêntica na Tabela Fato. Da perspectiva prática, esta é uma ideia terrível, pois teremos muita dificuldade em separar tais registros por meio da utilização de instruções SQL. Será difícil verificar a qualidade dos dados se diversos registros forem representados de forma idêntica em nossa Tabela Fato (KIMBALL e ROSS, 2010).
Tabela Fato Transacional
De acordo com Kimball e Ross (2013) uma Tabela Fato Transacional (Transaction Fact Table) é um tipo de tabela fato onde são mantidos os fatos na menor granularidade possível. Neste caso, é mantida uma transação para cada evento real. Uma Tabela Fato é do tipo transacional se:
- Cada evento é armazenado apenas uma vez;
- Há uma coluna de data indicando quando aquele evento ocorreu;
- Há um atributo identificador, que identifica cada evento unicamente.
A quantidade de registros da tabela é a mesma da origem.
Tabela Fato de Snapshot Acumulado
De acordo com (Kimball e Ross, 2013), uma Tabela Fato de Snapshot Acumulado (Accumulating Snapshot Fact Table) é menos frequente que as demais e corresponde a um processo previsível, cujos início e fim são bem definidos. Capturam os resultados de eventos-chave em uma relação de processos relacionados. As linhas da tabela são carregadas quando o primeiro evento ocorre, ou quando um marco histórico é alcançado. Diferentemente de outros tipos de Tabelas Fato, neste caso, linhas pré-existentes são atualizadas para refletir resultados correntes, ou acumulados de cada evento.
- Talvez usuários de negócio queiram analisar o seu pipeline de aquisições. Eles já possuem fatos atômicos individuais que capturam os detalhes ricos associados a cada evento de transação no pipeline, como a submissão de requisições de compra, emissão de pedidos de compra, recebimento de entregas, recebimento de faturas, emissão de pagamentos, etc. Embora cada um desses eventos compartilhem dimensões comuns, como Produto, Vendedor e Solicitante, as Tabelas Fato individuais possuem dimensões e métricas únicas.
- Suponha que algum usuário de negócio queira saber o quão rápido ordens de compra são emitidas após a submissão de requisições. Ou qual a discrepância entre a quantidade pedida versus o que foi recebido. Ou qual a duração ou tempo de atraso entre o recibo das faturas e o pagamento. Accumulating Snapshot Fact Table vêm para auxiliar neste tipo de análise.
- Accumulating Snapshot Fact Table é um tipo de Tabela Fato consolidada, que facilita a busca por determinado tipo de informação.
Natural Key
Uma Natural Key (NK) é uma chave única, composta por uma ou mais colunas, que identificam um registro unicamente, possuindo significado para o negócio. Uma NK possui relação semântica com os demais atributos em uma relação. Ex. CPF, CEP, RG, etc.
Dimensões de Etapa (Step Dimensions)
Processos sequenciais, como eventos de página da Web, normalmente têm uma linha separada em uma tabela de fatos para cada etapa de um processo. Para saber onde a etapa individual se encaixa na sessão geral, é usada uma dimensão de etapa que mostra qual número de etapa é representado pela etapa atual e quantas etapas a mais foram necessárias para concluir a sessão (Kimball e Ross, 2013).
Tabelas Fato Agregadas
Em adição às Tabelas Fato que armazenam dados atômicos relativos a fatos únicos de processos, tabelas agregadas são muitas vezes criadas. Essas tabelas combinam métricas de múltiplos processos em um nível comum de detalhe. São tabelas complementares às Tabelas Fato detalhadas, e não substitutas (KIMBALL e ROSS, 2013).
Agregações necessariamente agrupam e/ou removem dimensões presentes em Tabelas Fato atômicas. Deste modo, agregações sempre devem ser utilizadas juntamente com os dados atômicos, visto que estes possuem dimensões mais detalhadas.
Fatos Aditivos
No coração de qualquer Tabela Fato existe uma lista de fatos que representam medidas. Como a maioria das Tabelas Fato são grandes, com milhões ou até bilhões de registros, dificilmente utilizaremos um único registro para responder a alguma questão de negócio. Ao invés disso, geralmente recuperamos uma grande quantidade de registros, comprimidos em um formato amigável de soma (adição), contagem, média, valor máximo, valor mínimo, etc. Mas por questões práticas, o formato mais utilizado, de longe, é a soma. Deste modo, sempre que possível, devemos armazenar fatos aditivos (que permitam a soma). Deste modo, no exemplo da mercearia, não precisamos armazenar o preço unitário de um produto. Pois conseguiremos este valor simplesmente dividindo o valor da compra (dollar sales) pela quantidade comprada (unit sales) (KIMBALL e ROSS, 2010).
Alguns fatos, como saldos bancários e níveis de estoque, representam intensidades difíceis de expressar em um formato aditivo. Neste caso, tratamos este tipo de fato semi-aditivo como se fossem aditivos, mas antes de apresentar a informação para usuários de negócio, dividimos a resposta pela quantidade de períodos para termos o resultado correto. Esta técnica é chamada de média sobre o tempo (averaging over time) (KIMBALL e ROSS, 2010).
Algumas Tabelas Fato representam medições de eventos sem fato, esse tipo de tabela é chamada Tabela Fato sem Fato (factless fact tables). O exemplo clássico é o registro de atendimentos de estudantes de uma determinada turma para um dia em particular. As dimensões podem ser “dia”, “estudante”, “professor”, “curso” e “local”, mas veja que não há uma métrica claramente definida (KIMBALL e ROSS, 2010).
Dimensões Multivaloradas e Tabelas Ponte (bridge table)
Em um esquema dimensional clássico, cada dimensão anexada a uma tabela de fatos tem um único valor consistente com a granulação da tabela de fatos. Mas há uma série de situações em que uma dimensão é legitimamente multivalorada. Por exemplo, um paciente que recebe um tratamento de saúde pode ter vários diagnósticos simultâneos. Nesses casos, a dimensão multivalorada deve ser anexada à tabela de fatos por meio de uma chave de dimensão de grupo para uma tabela de ponte (bridge table) com uma linha para cada diagnóstico simultâneo em um grupo (Kimball e Ross, 2013).
Tabelas Fato Consolidadas
Frequentemente, é conveniente combinar fatos de vários processos em uma única Tabela Fatos consolidada se eles puderem ser expressos na mesma granulação. Por exemplo, dados de vendas podem ser consolidados com previsões de vendas em uma única Tabela Fatos para simplificar a tarefa de analisar os valores reais e os previstos, em comparação com a realização de uma operação de drill-across, usando Tabelas Fato separadas. Tabelas Fatos consolidadas aumentam a carga do processamento de ETL, mas facilitam a carga analítica nos aplicativos de BI. Esse tipo de Tabela Fato deve ser considerada para métricas frequentemente analisadas em conjunto (KIMBALL e ROSS, 2013).
Quando os fatos de vários processos de negócios são combinados em uma tabela de fatos consolidada, eles devem estar no mesmo nível de granularidade e dimensionalidade. Como os fatos separados raramente vivem naturalmente em um grão comum, você é forçado a eliminar ou agregar algumas dimensões para suportar a correspondência um-para-um, mantendo os dados atômicos em tabelas de fatos separadas. As equipes de projeto não devem criar fatos ou dimensões artificiais na tentativa de forçar a consolidação de dados de fatos com granulação diferente (KIMBALL e ROSS, 2013).
Tabelas Fato consolidadas contêm chaves estrangeiras para dimensões conformadas reduzidas, bem como fatos agregados criados pela soma de medidas de tabelas fato mais atômicas (KIMBALL e ROSS, 2013).
Fatos Agregados e Atributos de Dimensões
Usuários de negócio geralmente estão interessados em restringir a dimensão do cliente com base em métricas de desempenho agregadas, como filtrar todos os clientes que gastaram mais de um determinado valor no ano passado ou talvez durante a vida do cliente. Fatos agregados podem ser colocados em uma dimensão para restrição e como rótulos de linha para relatórios. As métricas geralmente são apresentadas como intervalos em faixas na tabela de dimensões. Os atributos de dimensão que representam as métricas de desempenho agregadas adicionam carga ao processamento de ETL, mas aliviam a carga analítica na camada de BI (Kimball e Ross, 2013).
Dimensões Genéricas Abstratas
Alguns modeladores são atraídos por dimensões genéricas abstratas. Por exemplo, seus esquemas incluem uma única dimensão de localização genérica em vez de atributos geográficos incorporados nas dimensões de loja, depósito e cliente. Da mesma forma, sua dimensão de pessoa inclui linhas para funcionários, clientes e contatos de fornecedores porque todos são seres humanos, independentemente de serem significativamente diferentes devido aos atributos coletados para cada tipo. Dimensões genéricas abstratas devem ser evitadas em modelos dimensionais.
Os conjuntos de atributos associados a cada tipo geralmente diferem. Se os atributos forem comuns, como um estado geográfico, eles devem ser rotulados de forma exclusiva para distinguir o estado de uma loja do estado de um cliente. Finalmente, despejar todas as variedades de locais, pessoas ou produtos em uma única dimensão invariavelmente resulta em uma tabela de dimensão maior. A abstração de dados pode ser apropriada no sistema de origem operacional ou no processamento ETL, mas afeta negativamente o desempenho e a legibilidade da consulta no modelo dimensional (Kimball e Ross, 2013).
Dimensões de comentário
Em vez de tratar os comentários de forma livre como métricas textuais em uma tabela de fatos, eles devem ser armazenados fora da tabela de fatos em uma dimensão de comentários separada (ou como atributos em uma dimensão com uma linha por transação se a cardinalidade dos comentários corresponder ao número de transações exclusivas) com uma chave estrangeira correspondente na tabela de fatos (Kimball e Ross, 2013).
Dimensões de Auditoria
Quando uma linha da tabela de fatos é criada pelo processo de ETL, é útil criar uma dimensão de auditoria contendo os metadados de processamento de ETL conhecidos no momento. Uma linha de dimensão de auditoria simples pode conter um ou mais indicadores básicos de qualidade de dados, talvez derivados do exame de um esquema de evento de erro que registra violações de qualidade de dados encontrados durante o processamento dos dados. Outros atributos de dimensão de auditoria úteis podem incluir variáveis de ambiente que descrevem as versões do código ETL usadas para criar as linhas de fatos ou os carimbos de tempo de execução do processo ETL (KIMBALL e ROSS, 2013).
Essas variáveis de ambiente são especialmente úteis para fins de conformidade e auditoria porque permitem que as ferramentas de BI façam uma busca detalhada para determinar quais linhas foram criadas com quais versões do software ETL.
Dimensão Conformada
Uma Dimensão Conformada (também chamada de Dimensão Compartilhada ou Dimensão Mestre) é uma dimensão que possui o mesmo significado para todas as Tabelas Fato que podem fazer junção à mesma. Uma das maiores responsabilidades em manter o DW está em estabelecer, publicar, manter e fazer valer as dimensões conformadas (KIMBALL e ROSS, 2010).
Tabelas de dimensão são conformes quando atributos com o mesmo nome em tabelas diferentes possuem o mesmo significado e conteúdo. Informações de diferentes Tabelas Fato podem ser combinadas em um único relatório por meio de atributos de dimensões conformadas. Quando um atributo conformado é utilizado como um label (isto é, no GROUP BY da instrução SQL), os resultados de diferentes Tabelas Fato podem ser alinhados na mesma linha em um relatório drill-across (KIMBALL e ROSS, 2013).
O estabelecimento de uma dimensão conformada é um passo muito importante. Uma dimensão conformada de Clientes, por exemplo, é uma tabela mestre de clientes com uma chave e atributos bem definidos e íntegros. É provável que a dimensão conformada de clientes seja aglomerado de dados de vários sistemas legados e possivelmente de fontes externas. O campo de endereço, por exemplo, deve ser constituído do endereço mais completo e atualizado possível para cada cliente (KIMBALL e ROSS, 2010).
A dimensão conformada de produtos, por exemplo, é a lista mestre de todos os produtos comercializados pela empresa, incluindo todos os atributos do produto e todas as suas agregações, como categoria e departamento. Uma boa dimensão de produtos, assim como uma boa dimensão de clientes, deve ter ao menos 50 atributos textuais (KIMBALL e ROSS, 2010).
Idealmente, a dimensão conformada de localização deve ser baseada em pontos específicos do mapa, como endereços específicos de ruas ou até mesmo latitudes e longitudes. Pontos específicos no espaço se acumulam em todas as hierarquias geográficas concebíveis, incluindo cidade-região-estado-país, bem como códigos postais, territórios e regiões de vendas (KIMBALL e ROSS, 2010).
A dimensão conformada de data quase sempre será uma tabela de dias individuais, abrangendo uma década ou mais. Cada dia terá muitos atributos úteis extraídos dos calendários legais dos vários estados e países com os quais a empresa lida, bem como períodos fiscais especiais e temporadas de marketing relevantes (KIMBALL e ROSS, 2010).
Dimensões conformadas são extremamente importantes para o DW. Sem uma adesão estrita às dimensões conformadas, o DW não pode funcionar como um todo integrado.
Dimensões reduzidas (Shrunken Dimensions)
Dimensões reduzidas são dimensões conformadas que são um subconjunto de linhas e/ou colunas de uma dimensão conformada original. São necessárias ao construir Tabelas Fato agregadas. Elas também são necessárias para processos de negócios que capturam dados naturalmente em um nível mais alto de granularidade, como uma previsão por mês e marca (em vez da data mais atômica e do produto associado aos dados de vendas). Outro caso de subconjunto de dimensão conformada ocorre quando duas dimensões estão no mesmo nível de detalhe, mas uma representa apenas um subconjunto de linhas (Kimball e Ross, 2013).
Slowly Changing Dimensions
Slowly Changing Dimensions (SCD) consiste em técnicas para gerenciamento da história de dados dimensionais em um DW. Deve-se ter em mente que as dimensões associadas às Tabelas Fato são afetadas com o passar do tempo. A mudança nos valores de dimensões pode ocorrer às vezes, em alguns casos, meramente para a correção de erros. Mas, às vezes, uma mudança em alguma descrição representa uma mudança verdadeira ocorrida em algum ponto do tempo, como a mudança do nome de um produto, ou de um cliente, por exemplo. Como tais mudanças ocorrem de forma inesperada, e esporadicamente, e com bem menos frequência que medidas em Tabelas Fato, o tópico é denominado Slowly Changing Dimensions (SCDs) (Kimball e Ross, 2013).
Os representantes de governança e administração de dados da empresa devem estar ativamente envolvidos nas decisões sobre o tratamento de mudanças em valores de dimensões; A TI não deve fazer determinações por conta própria (Kimball e Ross, 2013).
Kimball e Ross (2013) afirmam que são necessárias apenas três respostas básicas em caso de mudança de descrição em algum atributo de dimensão:
- Tipo 1: Substituição (Overwrite):
- Destruição da história. No exemplo acima, relatórios que filtram ou agrupam pelo campo “cidade” serão afetados. Usuários de negócio precisam ser avisados de que isso pode ocorrer. O DW precisa de uma política explícita e visível de utilização do Tipo 1, como por exemplo: “Erros serão corrigidos”, e/ou, “Não mantemos a história deste campo, mesmo se o seu valor for alterado”.
- Propagação da mudança. Todas as cópias distribuídas que dependem da dimensão deverão replicar as mudanças simultaneamente.
- Suponha que em um dia qualquer, o atributo “cidade” de Ralph Kimball, na Tabela Dimensão “empregado”, foi alterado de “Santa Cruz” para “Boulder Creek”. Mais tarde, somos avisados que isso se tratava de uma correção de erro, e não de uma mudança de localização. Neste caso, decidimos por atualizar o valor de “cidade”. Este é um exemplo clássico de uma mudança de Tipo 1. Adequado para casos de correção de erros e para situações em que a mudança não afete a história.
- Embora o Tipo 1 seja o tratamento mais simples e direto para lidar com alterações em valores de dimensões, os seguintes pontos devem ser observados:
- Tipo 2: Adição de um novo registro de dimensão:
- O Tipo 2 requer que generalizemos a chave primária de “empregado”. Neste caso, é recomendado que a chave primária da relação “empregado” seja algo desconectado da chave primária da relação original, proveniente do sistema relacional. Indica-se, por exemplo, a criação de uma chave primária sequencial. Este tipo de chave primária é chamado surrogate key (chave substituta).
- Vamos alterar o cenário anterior e supor que Ralph Kimball de fato se mudou para uma nova cidade em 18/07/2020. Digamos que a política da organização consiste em manter no DW o histórico exato de endereço residencial de cada funcionário. Esta então seria uma situação clássica para aplicação do Tipo 2.
- O Tipo 2 exige que seja incluído um novo registro na relação “empregado”, referente ao novo valor para o campo “cidade”. Este tratamento resulta nos seguintes efeitos:
- Tipo 3: Adição de um novo atributo.
- Embora os tipos 1 e 2 vistos anteriormente sejam as técnicas principais utilizadas para tratamento de mudanças em dimensões, precisaremos de uma terceira técnica para abarcar situações em que precisamos alternar entre realidades distintas. Diferentemente de atributos físicos que podem ter apenas um único valor em determinado momento, alguns atributos atribuídos pelo usuário podem legitimamente ter mais de um valor por vez, dependendo do ponto de vista do observador. Por exemplo, uma categoria de produto pode ter mais de uma interpretação. Em uma papelaria, uma caneta de marcação pode ser assimilada na categoria de bens domésticos, ou na categoria de suprimentos artísticos. Usuários e aplicações de BI precisam ter a possibilidade de escolha, em tempo de execução, de qual realidade será aplicada naquele momento.
- O requisito por uma realidade alternativa de visualização de um atributo de dimensão é geralmente acompanhado do requisito de se permitir a separação de versões da realidade nos dados passados e futuros, mesmo que a requisição da inclusão dessa nova realidade tenha chegado ao DW no momento presente.
- Tais requisitos podem ser alcançados por meio da adição de uma nova coluna para cada realidade alternativa do atributo de dimensão. Com esta abordagem, usuários e aplicações de BI podem, a qualquer momento, alterar a realidade por meio da seleção do campo criado para a realidade desejada.
É comum uma mesma dimensão possuir estratégias de tratamento de mudanças específicas para cada atributo (Kimball e Ross, 2013).
Dimensões Degeneradas
Em diversas situações onde a granularidade é um filho de algum evento maior, a chave natural deste evento pai acaba tornando-se um órfão durante o design. No exemplo dado pela Figura 1, a granularidade definida é uma linha da nota de venda (ticket). O número do ticket (ticket number) é a chave natural da nota de venda. Como os dados do ticket foram espalhados em dimensões de contexto, o número do ticket foi deixado para trás, sem atributos específicos. Neste caso, o número do ticket é incluído diretamente na Tabela Fato. Chamamos esta situação de dimensão degenerada (degenerate dimension). O número do ticket é útil pois é a cola que segura os itens presentes em uma mesma nota (KIMBAL e ROSS, 2013).
Mantendo a Granularidade na Modelagem Dimensional
Embora teoricamente qualquer mistura de fatos possa ser incluída em uma mesma tabela, um design dimensional apropriado permite apenas fatos na mesma granularidade (mesma dimensionalidade) coexistirem em uma mesma Tabela Fato. Uma granularidade uniforme garante que todas as dimensões serão utilizadas por todos os fatos, reduzindo drasticamente a possibilidade de equívocos durante a combinação de dados de diferentes granularidades. Por exemplo, geralmente não faz sentido adicionar dados diários a dados anuais. Quando você tem fatos em duas granularidades diferentes, coloque-os em tabelas separadas (KIMBALL e ROSS, 2010).
O poder do modelo dimensional vem da sua aderência a uma granularidade específica. Uma definição clara da granularidade de uma Tabela Fato possibilita a definição dos modelos físico e lógico. Uma definição confusa ou imprecisa impõe ameaças em todos os aspectos de design, desde os processos de ETL até as ferramentas de visualização que farão uso do dado (KIMBALL e ROSS, 2010).
A granularidade de uma Tabela Fato é a definição de negócio de uma medida que resulta na criação de um registro fato (fact record). Toda a definição de granularidade deve ser iniciada do menor nível possível (atômico), relativo para o evento gerador do fato. Manter aderência à granularidade significa construir Tabelas Fato em torno de cada evento de medição de processos de negócio atômicos. Essas tabelas são simples de serem implementadas, mas proveem uma fundação durável e flexível, capaz de endereçar questões de negócio e relatórios do dia-a-dia (KIMBALL e ROSS, 2010).
Pense Dimensionalmente
Ao reunir os requisitos para uma iniciativa de DW/BI, você precisa ouvir e em seguida, sintetizar as descobertas em torno dos processos de negócios. Quando especificar o escopo de um projeto, mantenha o foco em um único processo de negócio por projeto, evitando a elaboração de dashboards com inúmeros processos de negócio associados (KIMBALL e ROSS, 2013).
Embora seja fundamental que a equipe de DW/BI se concentre nos processos de negócios, é igualmente importante manter o alinhamento com a equipe de negócios. Devido às políticas históricas de financiamento da TI, a empresa pode estar mais familiarizada com implantações de soluções a nível departamental. Você precisa mudar a mentalidade dos envolvidos para a implementação de soluções de DW/BI para uma perspectiva de processos de negócios. Felizmente, gestores de negócio geralmente adotam essa abordagem porque reflete seu pensamento sobre os principais indicadores de desempenho. Além disso, eles viveram com inconsistências, debates incessantes e reconciliações sem fim causadas pela abordagem departamental, então eles estão prontos para uma nova abordagem (KIMBALL e ROSS, 2013).
Ao atuar com as lideranças de negócios, classifique cada processo em escala de valor e viabilidade e, em seguida, ataque primeiramente os processos com as pontuações de maior impacto e viabilidade. Embora a priorização seja uma atividade conjunta com o negócio, sua compreensão subjacente dos processos de negócios da organização é essencial para sua eficácia e subsequente capacidade de ação (KIMBALL e ROSS, 2013).
Os programas de governança de dados devem se concentrar primeiro nas dimensões principais. Dependendo do setor da indústria, a lista pode incluir data, cliente, produto, funcionário, aluno, corpo docente e assim por diante. Pensar nos substantivos centrais usados para descrever o negócio se traduz em uma lista de esforços de governança de dados a serem liderados por especialistas no assunto e representantes da comunidade de negócios. Estabelecer responsabilidades de governança de dados para esses substantivos é a chave para implementar dimensões que entreguem consistência e atendam às necessidades de negócios de filtragem analítica, agrupamento e rotulagem. Dimensões robustas se traduzem em sistemas DW/BI robustos (KIMBALL e ROSS, 2013).
Modelos dimensionais devem ser elaborados em colaboração com a área de negócios, e não por indivíduos que não entendem completamente o negócio e suas necessidades (KIMBALL e ROSS, 2013).
Schemas de Eventos de Erros
Gerenciar a qualidade de dados em um Data Warehouse requer um sistema abrangente de qualidade que testa os dados à medida que fluem dos sistemas de origem para a plataforma de BI. Quando o script de qualidade de dados detecta um erro, esse evento é registrado em um esquema dimensional especial que está disponível apenas no backend do processo de ETL. Esse esquema consiste em uma tabela de fatos de evento de erro cuja granulação é o evento de erro individual e uma tabela de fatos de detalhes de evento de erro associada cuja granulação é cada coluna em cada tabela que participa de um evento de erro (KIMBALL e ROSS, 2013).
Surrogate Key
Uma Surrogate Key (SK), ou chave substituta, assim como uma Natural Key (NK), é um identificador único em uma tabela, capaz de identificar unicamente cada registro. No entanto, uma SK não possui nenhuma relação semântica com os demais atributos de uma tabela. É apenas uma valor, geralmente inteiro e sequencial, gerado com o propósito de ser a chave primária da relação.
Kimball e Ross (2010) recomendam que todas as Tabelas Dimensão tenham uma SK, mesmo aquelas com tratamento SCD do Tipo 1. Isto irá isolar o DW de surpresas ao incorporar novos dados provenientes de fontes com suas próprias ideias sobre chaves. Ainda de acordo com os autores, a utilização de SKs tornará o banco de dados mais rápido.
Existem momentos em que a utilização de SKs em Tabelas Fato (FSKs) é importante. Embora FSKs não tenham utilidade para o negócio, elas possuem diversas vantagens internamente para o DW:
- FSKs identificam um fato unicamente;
- Como FSKs são inseridas sequencialmente, uma rotina de inserção de novos registros terá as FSKs em uma faixa contínua;
- Uma FSK permite a substituição de update por insert-deletes;
- Uma FSK pode se tornar uma chave estrangeira em uma tabela fato de menor granularidade.
Uma NK pode não ser durável, visto que não teremos controle sobre possíveis mudanças de chave nas fontes de origem. NKs podem ser originárias de mais de uma fonte, e neste caso, cada fonte de dados pode utilizar uma NK diferente para um mesmo processo de negócio.
Data Profiling
Ao longo do processo de modelagem dimensional, a equipe precisa desenvolver uma compreensão cada vez maior da estrutura, conteúdo, relacionamentos e regras de derivação dos dados de origem. É necessário verificar se os dados estão em um estado utilizável, ou se ao menos suas falhas podem ser gerenciadas, entendendo o que é necessário para convertê-los para o modelo dimensional. O objetivo da atividade de data profiling (verificação do perfil dos dados) é a exploração do conteúdo e dos relacionamentos reais dos dados no sistema de origem, ao invés de depender de documentação, talvez incompleta ou desatualizada.